Is The Stupid is spreading?
Nope, this Stupid Trick is pretty good. I am however continuing my pattern of stealing good ideas highlighting all that is best in the Essbase world with this ostensibly-simple but quite useful Stupid Trick from Martin Slack.
Migration, drives, and DATAEXPORT
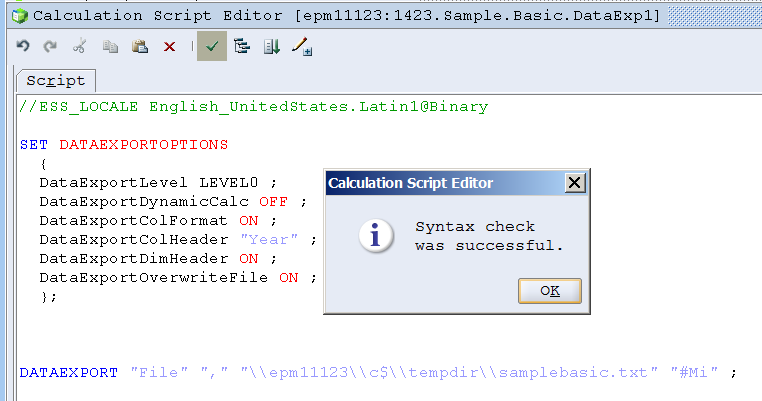
I and many others have covered using DATAEXPORT as a way to get data out of BSO cubes. There are quite a few issues when writing to relational tables (it always appends, performance isn’t all that great, batch inserts amazingly do not work with 64 bit Essbase, etc.) so the most common way is to write to flat file. As one might guess, writing to a flat file usually (I suppose one could write to a default location but who does that?) requires defining a drive name with syntax that looks something like:
DATAEXPORT "File" "," "c:\\tempdir\\samplebasic.txt" "#Mi" ;
And yes, before anyone gets too excited about me using MVFEDITWWW, aka Sample.Basic, as an example for this, this technique works with Really Big BSO Databases (so RBBD?) as well.
Moving on from my justification of using Sample.Basic, can anyone spot the issue with the above? I’m sure the more perceptive of you note that I am pointing to an explicit drive (C:) and directory (tempdir). What happens when I migrate this awesome bit of code from my VM to something real? Or, more to your real world needs, what happens when you write something like this on your development server, which uses the C drive (‘coz you are nuts – who uses that drive for anything data-related, but I digress yet again) and move it to something more real, like the D or E or F drive over in QA and Production. And what if you’re exporting data not to a local drive but to a network mapped drive (the purpose of exporting data is to make it available for some other process, likely on another server, to transform)?
You change the code. But of course you shouldn’t.
Here’s the What You Shouldn’t Do approach:
NB – I am using UNC names as I may very well want to push this output to another server. At least if I hard code this I can, with only a bit of change, flip from one server to another.
Some of us devil-may-care Essbase hacker types believe (in the immortal words of a consultant I knew long, long ago), “There’s no test like production” and, I suppose in an insane way that’s true. However, this blog’s audience is of the Best and Brightest and we B&Bers know that one never, never, never does this. Right? Right.
So with this in mind, what’s the obvious way to get round this? Essbase has this cool bit of functionality called an Essbase Substitution Variable. One could hard code the explicitly defined file name (full path including drive, folder path, and file name) to a Sub Var, but then the issue would be that if you have more than one calc script writing out a DATAEXPORT, you’d then have to have those explicit path Sub Vars for each one of the files. And even worse, if the different environments have different mapped drives or different local drives that bump up against the development drive definitions it all gets a bit horrific.
Wouldn’t it be better to not hardcode much of anything except the file name and maybe part of the path? And get away from explicit drive names? And even explicit folder names? Yes.
Sub Vars with a twist
So if the obvious (isn’t it) way to solve hardcoding of path names is to use Sub Vars, and the even better way to avoid hardcoding path names is to use a Sub Var that only specifies the drive and the path, how oh how oh how to do it? It isn’t obvious.
Start with easy
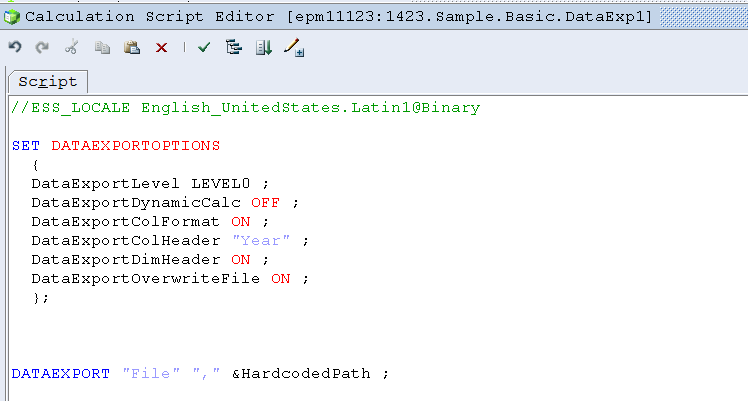
The most straightforward approach is to simply put the entire path into a variable as per below:
And then in the code reference it like so:
Does it work? Oh yes:
That’s great but as noted to use this approach for more than one DATAEXPORT target, one would have to have multiple variables and that’s messy.
So if we think about strings, and how they can be concatenated, it seems reasonable that a concatenation of a variable that specifies a drive and folder path with the file name should provide the string that Essbase needs and be flexible at the same time.
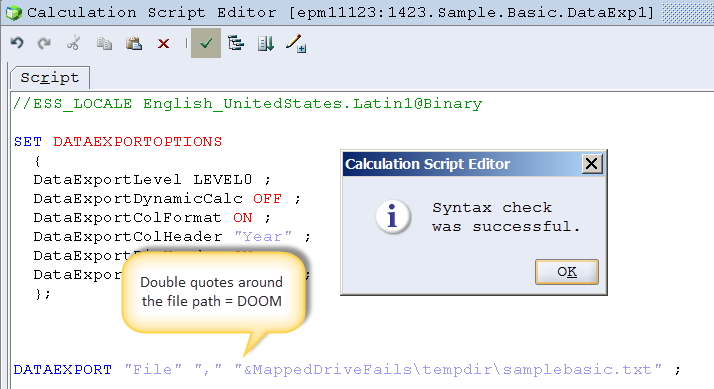
What to do with the double quotes is a bit of a puzzle. The non-variable approach is to wrap the path and file name in double quotes, the HardcodedPath variable has that explicitly named file in double quotes in the variable value thus passing the quote delimters. The question then becomes how do you handle the leading and trailing quotes when part of the path name is a variable and the other a hard coded file name that requires that terminating double quote?
Let the name of the variable below be a clue.
Oddly, on validation, it passes:
The doom and gloom text box is not from EAS but instead yr. obt. svt.’s idea of humor such as it is.
So, it syntax checks but when executed, nada:
We now know that, at least so far, a variable with the double quotes as part of the variable value works, but when those double quotes are wrapped around the variable value (which does not have those quotes) it fails.
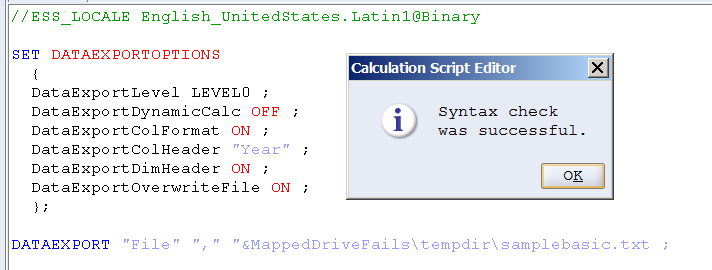
NB – For those of you who might think the file was written out with the name &MappedDriveFails\tempdir\samplebasic.txt because everything within the double quotes is treated as a literal, I am here to tell you that it is not; it simply doesn’t get written to disk.
We are now at the Stupid Trick
Before I go any further, here are some further oddities.
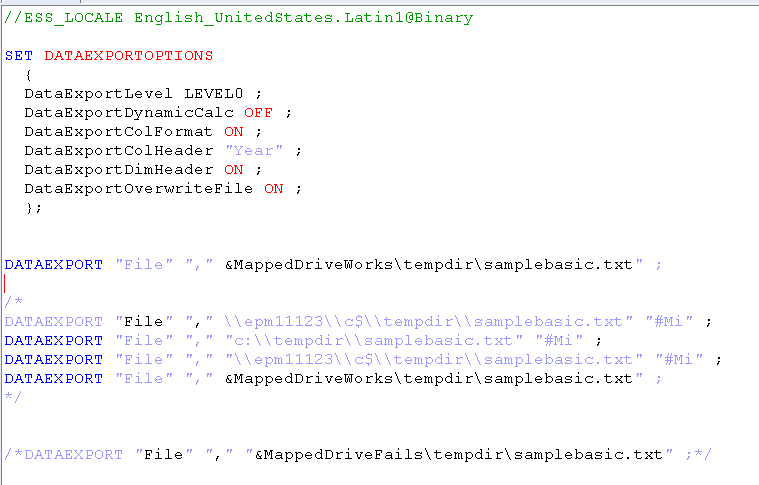
Can you get round double quotes altogether? It validates… 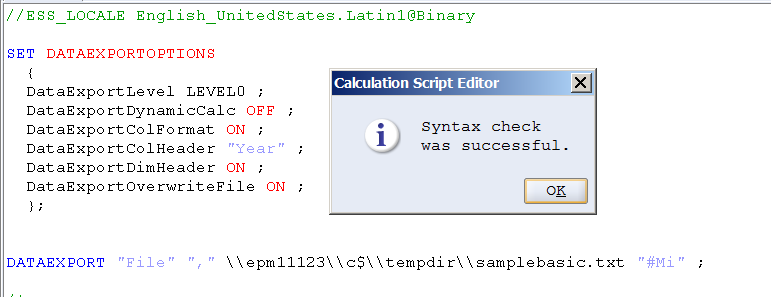
But it doesn’t work.
And you cannot hardcode the path and then terminate with a double quote (not totally sure why you want to do this, but I note it for the sake of completeness). It does validate… 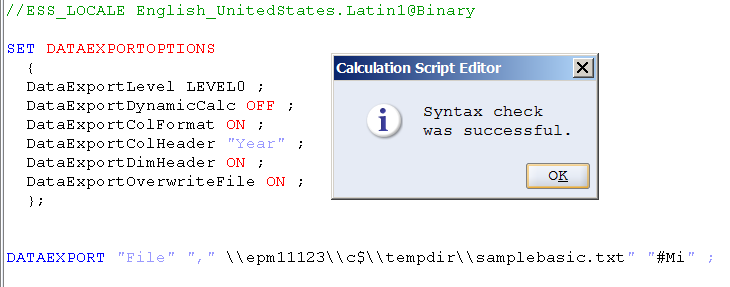
But doesn’t work. I wouldn’t put a lot of stock into Essbase’s DATAEXPORT validation process.
The not so obvious answer
Really, this is not obvious, at least to me. Hopefully not you, either, else I will feel even more stupid than I usually do. Which lately is quite a bit.
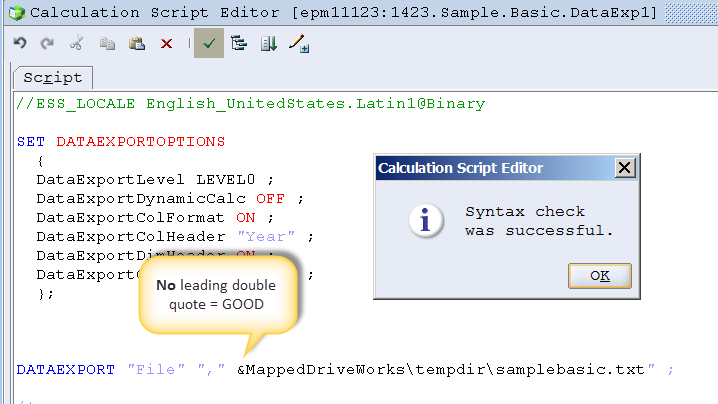
Here’s the approach as taught by Martin: put a double quote at the beginning of the variable value and then do not use a double quote to terminate the file name in the calc script. It sounds and looks really wonky but it works.
This bears repeating
Don’t put a double quote on the end of the file target. Let me restate that – the variable value has a leading double quote – "\\epm11123\c$ but the terminating file name does not have a terminating double quote. It looks something like this:
DATAEXPORT "File" "," &MappedDriveWorks\tempdir\samplebasic.txt ;
Again the variable value is "\\epm11123\c$. That’s a leading double quote. Pay Attention Because This is Important. As is the (how many times have I stated this?) the fact that there is no trailing double quote. See, I told you this was a Stupid Trick. And I think I told you twice. At least.
Let’s look at the results
Here we are in the EAS variable editor:
And then, in the calc script, do not use a trailing double quote (so the third time I mention this?).
Here’s the proof (I of course expect you, Gentle Reader, to believe absolutely none of this so Happy Testing):
Ah, you say, surely this can be dealt with by putting a double quote into the calc script itself and then using &MappedDriveFailes which does not have a leading double quote. That mimics what’s done above (at least in theory), right?
Alas and alack, although of course it validates it doesn’t work.
Going back to what works, how the calc script editor handles the lack of a leading double quote is a bit amusing:
So the approaches that don’t work do validate, do color code commented lines as green, but again don’t work. The approach that does work does validate (although again this isn’t much to write home about), doesn’t handle color coding, and then does work. Terrific.
This is what I love about Stupid Tricks
What’s the criteria?
It is pretty useful.
It is not obvious.
It is clever.
It really doesn’t make sense, but it works.
I think this use-double-quotes-here-but-not-here approach hits the mark on all four points. Going forward, I won’t specify DATAEXPORT paths any other way.
Thanks Martin for letting me steal your idea.
Be seeing you.