Introduction
I know many (some? one or two?) of you are coming to OOW, or will be in the Bay Area vicinity next week.We (Tim Tow and I) are hosting an Essbase/EPM meetup at Specchio-Ristorante at 8 pm, Tuesday 2 October.
What's it going to be about? Agenda tbd, but I hope you enjoy improvisational situations because that's exactly what it's going to be. What I would expect:
- Networking
- Knowledge sharing
- Completely
legal drugs in liquid form at the cash bar. No, not antipsychotics in
liquid suspension, but I do believe Specchio has a liquor license.
OTOH, if it's a really trying conference, I may be drinking coffee. Or
thinking maybe Risperdal might be an option. It might be that good
of a conference. We shall see. Once upon a time, I worked for the company that
invented that drug. No, I am not a pharmacologist. I
did however replace their IRI Express (soon to become Oracle OLAP Server)
instance with Essbase. :)
- Hanging
out with like-minded people. Which I suppose is pretty darn close to
Networking, so I think I am done with the listing of benefits.
There's only room for 50, and Tim and I have both rsvp'd, so that means 48 slots are open as of this writing.
Here’s the gen
Here's the meetup invitation:http://www.meetup.com/Oracle-Open-World-Essbase-EPM-meetup/events/83903872/And the restaurant's web site:http://www.ristorantespecchio.com/about/I hope you can make it -- it should be a lot of fun.
Introduction to the guide
I was asked in in this thread over on the Network54 Essbase board
to post a guide to Hyperion Financial Reports batch bursting I wrote a
while back. I’m happy to share what I came up with but first a couple
of caveats:
- I have redacted identifying information from the screenshots. It’s usually pretty obvious where this has happened.
- If
you have questions about this, go ahead and make comments but
unfortunately, I can’t reproduce the environment I did this one because:
- I
wrote this for EPM 11.1.2.0 (so an almost two year old release). I
have no idea if the
defects/bugs/weirdness/obvious-stuff-that-I-am-too-dense-to-see have
been resolved or not in 11.1.2.1 and 11.1.2.2. Mercifully, I have not
been called upon to do more with batches since writing this document.
- Some
of the issues I encountered were, I think, caused by a
less-than-perfect installation. I could rant on and on about how bad it
was but it would bore everyone, even me. At the time, I asked someone I
know in infrastructure what he thought it would take to resolve all of
the issues (oh, I had a working issues list). The reply? “I wouldn’t
touch that with a 40 foot barge pole. If I were to come in, I would
insist on a complete reinstallation on a clean box.” In other words, nuke and pave.
I mention this not to reflect the frustration we application
developers encounter when an install is bad, but to note that some of
the general weirdness may be because the software wasn’t “right”.
- I
wrote this in the form of a step-by-step tutorial. I never did find
one on the web – I thought for sure there would be one but my google-fu
failed me. Maybe there’s one now, but I sort of doubt it.
- Contrary to what I wrote in that thread, doing all of this is not 23 steps, but instead:
- 24 steps (23 to create + 1 to view) to create that scheduled batch
- 6 steps to import a bursting file (and yes, I explain what a bursting file is) into Workspace
- 6 more steps to applying the bursting file into the batch scheduler
- Although I am somewhat math-challenged, that means this is a 36 step process. It's almost the 39 Steps.
And with that out of the way, enjoy.
Background
Briefly, there are six kinds of Financial Reports documents typically encountered in a Planning implementation:
- Financial Reports – the base Essbase/Planning report
- FR Books – collections of FRs using, where applicable, a common POV to drive all reports within a book
- FR
Batches – Objects that contain reports and books. A batch can contain a
single report, multiple reports, a single book, multiple books, mixes
of reports and books, etc.
- FR
Scheduled Batches – Scheduler (Workspace has its own, reports-only
scheduler) of FR Batches and their Books and reports. Scheduled objects
can get written to Workspace folders, zip files, and emails.
- Burst
batching – A way to parameterize scheduled batches and overload single
dimension selections (only one dimension can be bursted and yes that is a
strange word for it) with either manually selected members or members
driven through imported burst files.
- Bursting files – These are comma-delimited files used to drive burst batching
How to create a Scheduled Batch in Workspace 11.1.2.0
It’s just a simple 23 step procedure to define a scheduled batch.
Creating a book
1) After
creating a FR report, create a FR book by logging into Workspace and
clicking on the Explore button. Then select File->New->Document,.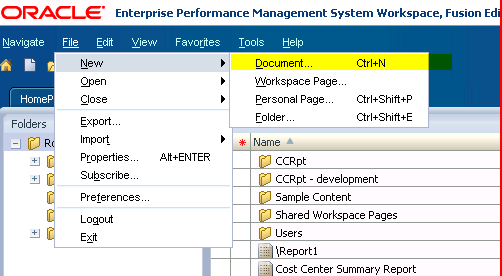 2) Select “Collect Reports into a book”
2) Select “Collect Reports into a book”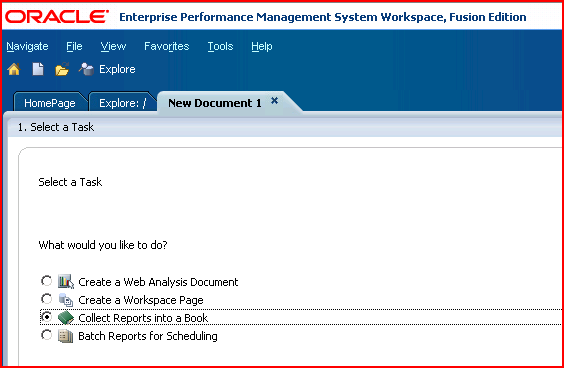 3) Pick
the report you want to incorporate into the book. Books commonly
contain more than one report but that is not a requirement.
3) Pick
the report you want to incorporate into the book. Books commonly
contain more than one report but that is not a requirement.
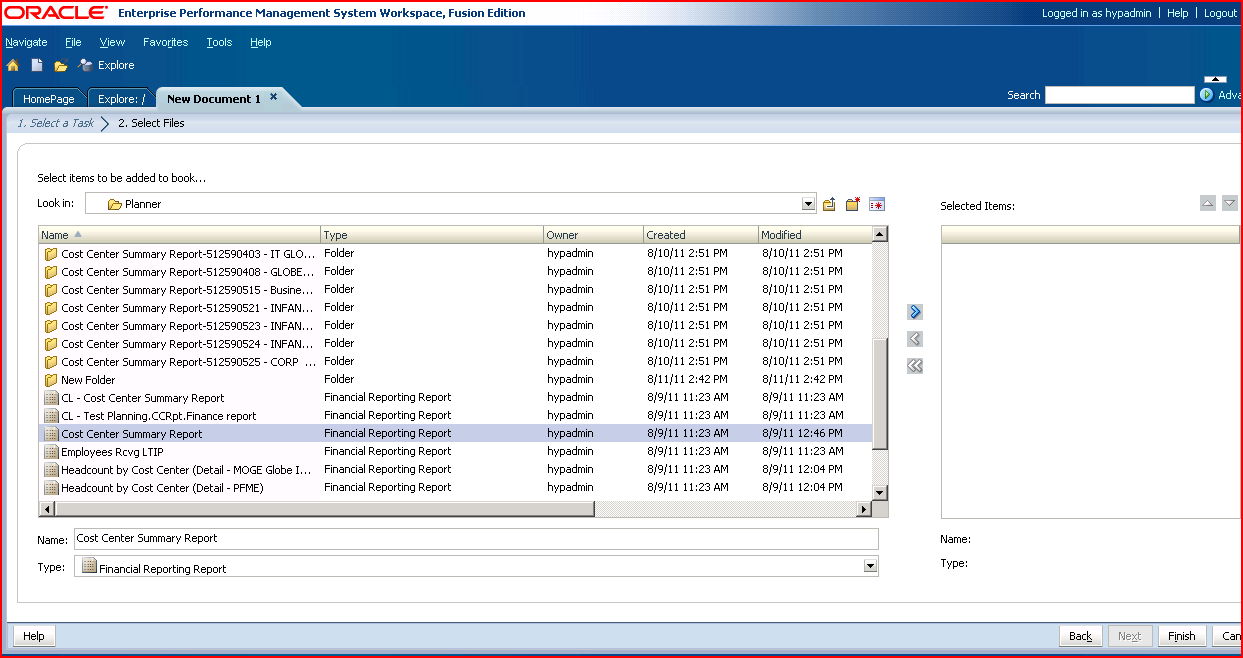 4) Move the report(s) over to the right hand list box and when complete, click “Finish”.
4) Move the report(s) over to the right hand list box and when complete, click “Finish”. 5) The data sources in the report(s) will show up in the book. These will be driven by the book’s POV.
5) The data sources in the report(s) will show up in the book. These will be driven by the book’s POV. 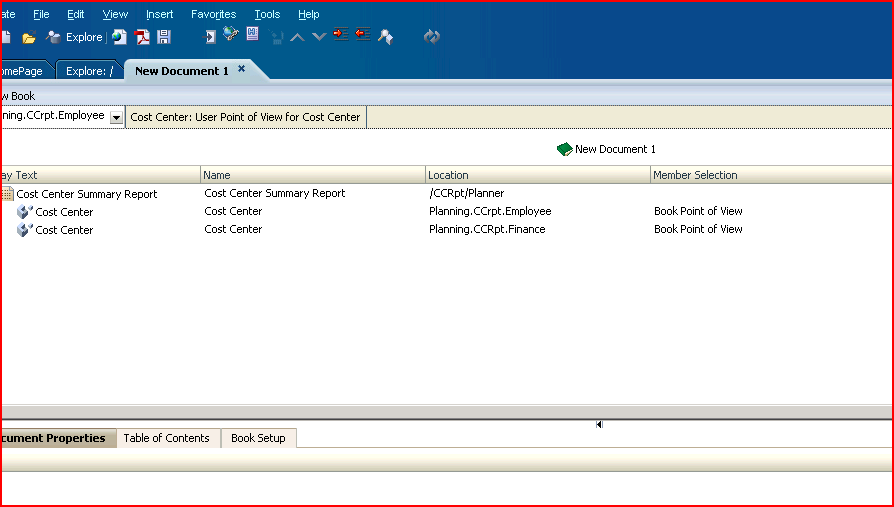 6) If you wish to get rid of the book’s table of contents, deselect it as shown below.
6) If you wish to get rid of the book’s table of contents, deselect it as shown below.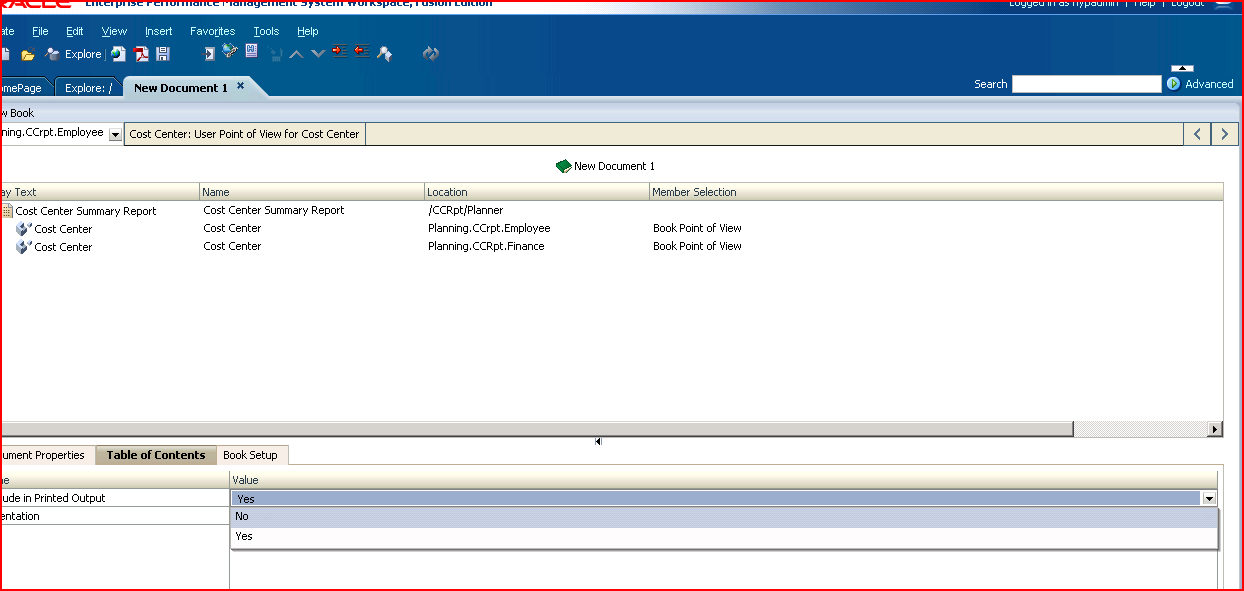 7) To force the save of the book, close the document; you will be prompted to save the book.
7) To force the save of the book, close the document; you will be prompted to save the book.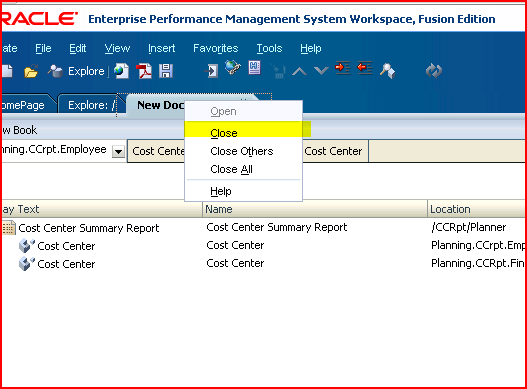 8) Save the book to whatever name and location you desire.
8) Save the book to whatever name and location you desire.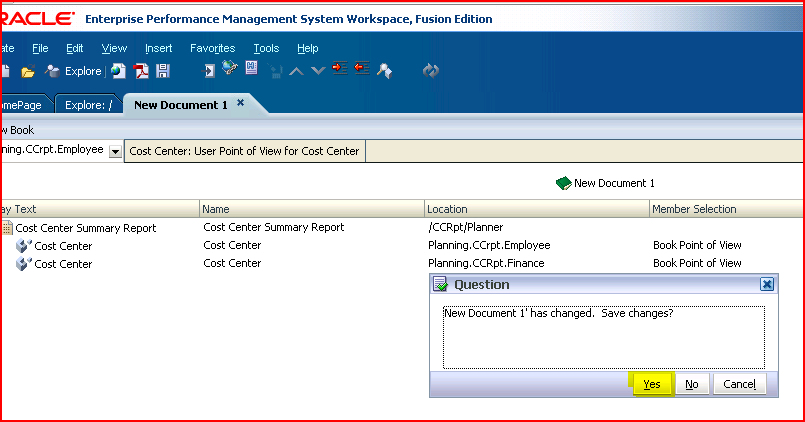 9) This book will be used in the batch.
9) This book will be used in the batch.
Creating a batch
10) Go to File->New->Document again, but this time select “Batch Reports for Scheduling”.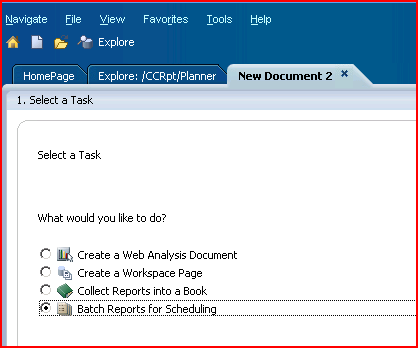 11) Batches
can be just a single or multiple books and reports. To see them in the
file selector, use the dropdown at the bottom to toggle between the
different kinds of base documents.
11) Batches
can be just a single or multiple books and reports. To see them in the
file selector, use the dropdown at the bottom to toggle between the
different kinds of base documents.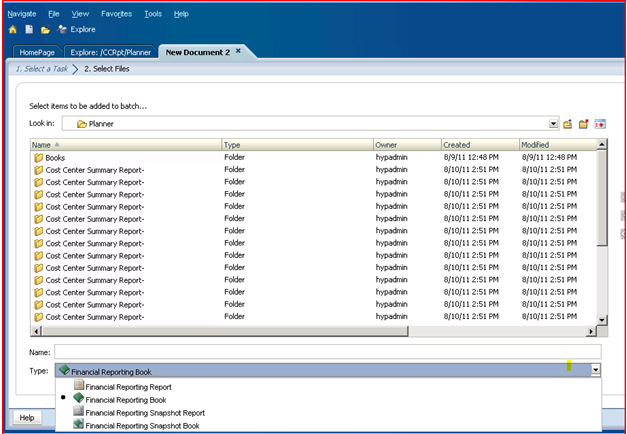 12) Move the object you want to put into the batch over to the right.
12) Move the object you want to put into the batch over to the right.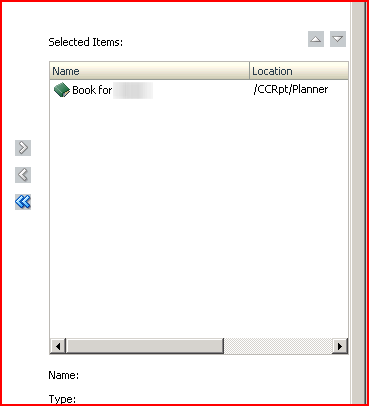 13) Again, close the document to force a save action.
13) Again, close the document to force a save action. 14) Save the batch.
14) Save the batch.
Scheduling a batch
Creating the scheduled batch
15) Schedule the batch by going to the Navigate->Batch Scheduler menu. 16) In the Batch Scheduler screen, right click and select “New Scheduled Batch”. This will launch the scheduled batch wizard.
16) In the Batch Scheduler screen, right click and select “New Scheduled Batch”. This will launch the scheduled batch wizard.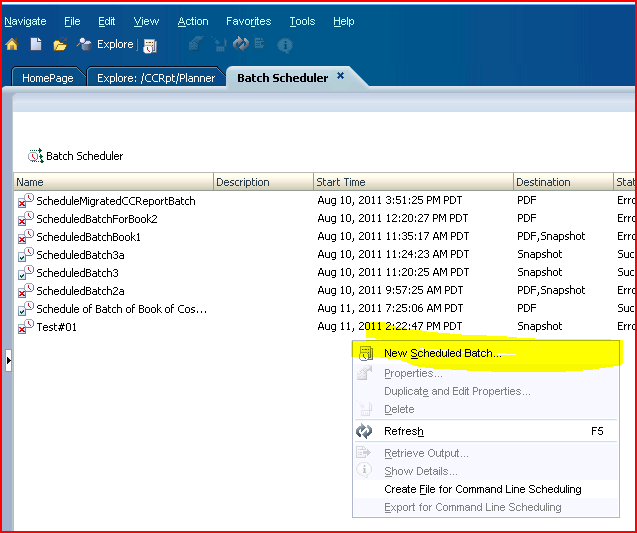 17) Name
the batch. You can make the batch a one-tme affair by selecting “Delete
Scheduled Batch Entry from Scheduler if Completed Successfully”. Do
not do this as creating a batch is fairly painful, as you may have
noticed. Click on Next to move to the next step.
17) Name
the batch. You can make the batch a one-tme affair by selecting “Delete
Scheduled Batch Entry from Scheduler if Completed Successfully”. Do
not do this as creating a batch is fairly painful, as you may have
noticed. Click on Next to move to the next step.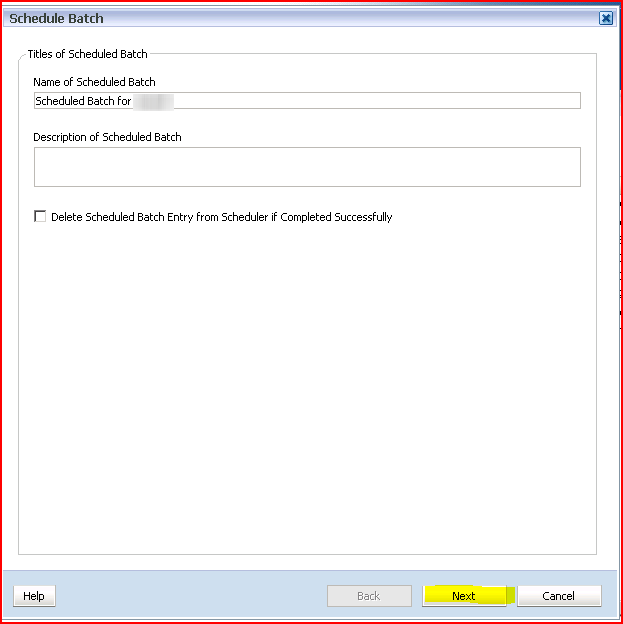 18) Select
the batch you want. In this example, it’s “Batch for XXXXXXXXXXX”.
After entering the name, click on Next to move to the next step.
18) Select
the batch you want. In this example, it’s “Batch for XXXXXXXXXXX”.
After entering the name, click on Next to move to the next step.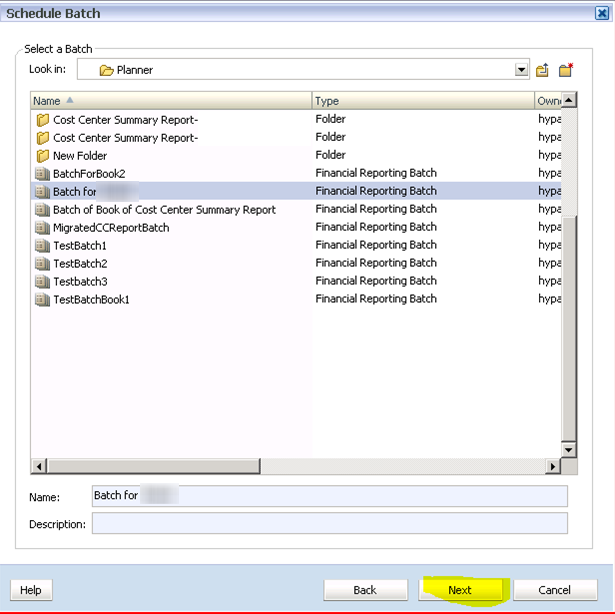 19) You will be prompted to log in to both FR and Essbase with an administrator id. I do not recommend a specific userid like CameronTheConsultant as these ids get terminated.
19) You will be prompted to log in to both FR and Essbase with an administrator id. I do not recommend a specific userid like CameronTheConsultant as these ids get terminated. 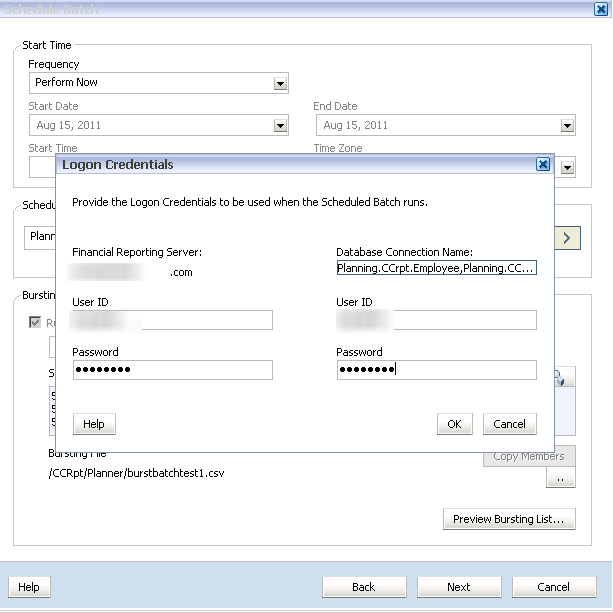
Selecting members for data connections
20) Individually
select the connections (the All option doesn’t work, see Oracle Support
ID 1097787.1) and select (usually) identical cost centers for each data
source.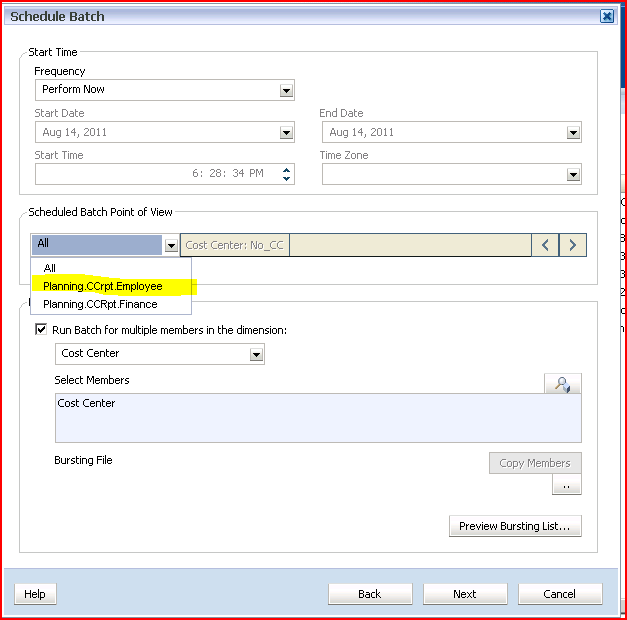 21) There’s a big
bug in FR batches – as far as I can observe, when the scheduled batch
is edited the Selected Members appear to be defined (and are shown in
the Select Members text box) but are not. The only way around this bug
is to select the individual data connections and click on the Copy
Members button to reapply the Cost Center members.
I
have also found that clicking on the Preview Bursting List button for a
given data source will deselect the selected members for the other data
source. To make sure both data sources are selected, click on the Copy
Members button for both data sources and do not use the Preview
Bursting List.
Click on Next to move to the next screen.
21) There’s a big
bug in FR batches – as far as I can observe, when the scheduled batch
is edited the Selected Members appear to be defined (and are shown in
the Select Members text box) but are not. The only way around this bug
is to select the individual data connections and click on the Copy
Members button to reapply the Cost Center members.
I
have also found that clicking on the Preview Bursting List button for a
given data source will deselect the selected members for the other data
source. To make sure both data sources are selected, click on the Copy
Members button for both data sources and do not use the Preview
Bursting List.
Click on Next to move to the next screen.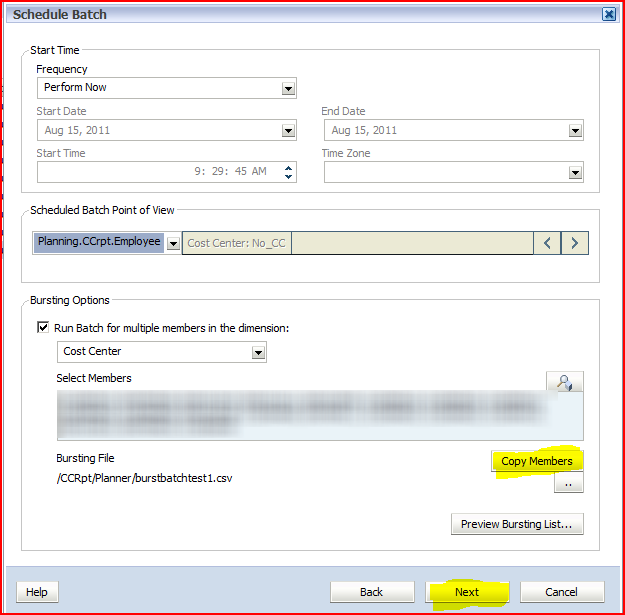
Defining where the batch output goes
22) Select “Export as PDF” and “Export to an external directory”. Click on Next to run the batch.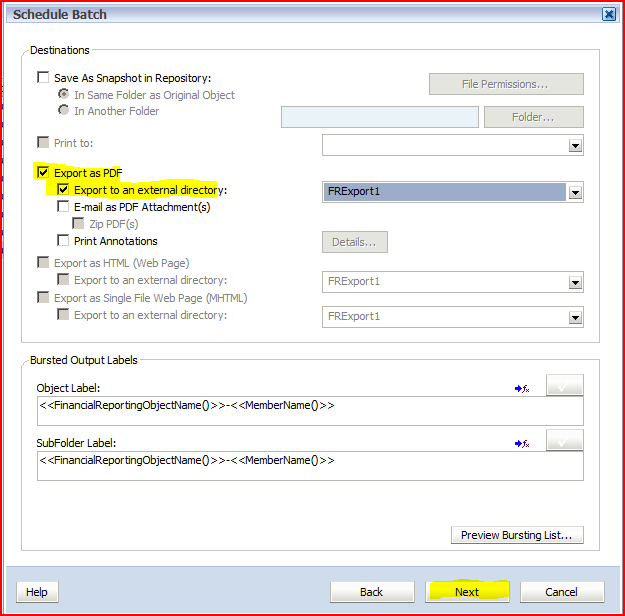 23) A confirmation dialog box will appear.
23) A confirmation dialog box will appear.
Reviewing the output
24) The external directory FRExport1, as defined through the FRConfig.cmd utility on the Financial Reports server, corresponds to \\yourservername\f$\FRExport1. The output structure is as below.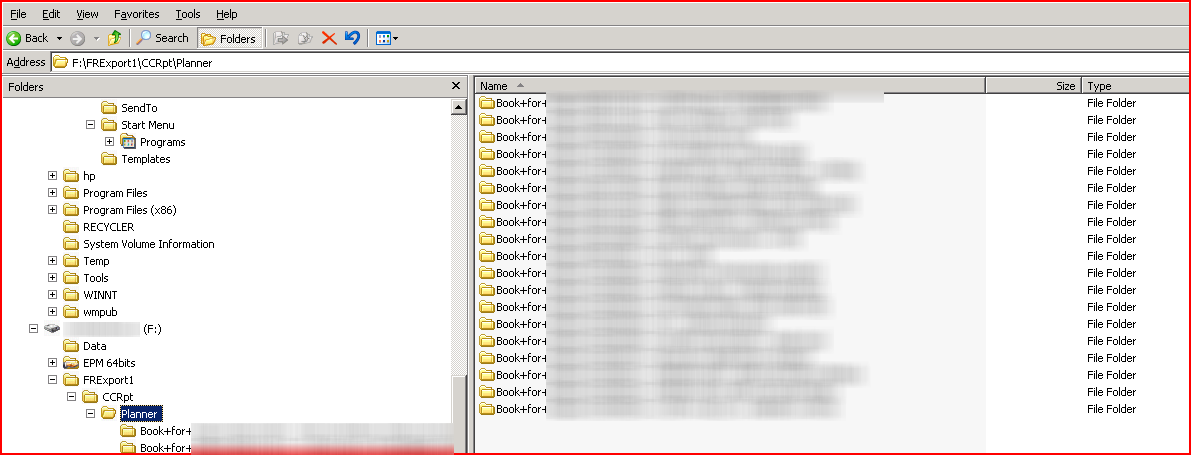
Bursting files in scheduled batches
Bursting
files are comma delimited files used to externally drive batch bursting
member selections. Given the bugs in FR batch scheduling, bursting
files also provide a way to quickly and consistently select members in
the Bursting Options.
For
Oracle’s take on the bursting file parameters see:
http://download.oracle.com/docs/cd/E17236_01/epm.1112/fr_webuser/scheduler_wizard_fr.html
Bursting file fields
dimension_dimensionname
In
the CCRpt example, the column name is dimension_Cost Center. Within
the field, the member values are the cost center numbers. Per the
documentation, member names must match on case. Only one dimension per
burst batching file can be defined.
subfolder_name
The
name of the folders underneath the main one defined in the batch
schedule. The CCRpt example uses
<<FinancialReportingObjectName()>>-<<MemberAlias()>>
which passes the name of the book and the member alias from the
dimension_dimensionname column into the sub folder name. Other valid tags are <<MemberName()>>, <<BatchPovMember(DataSrcName,DimName)>>, <<BatchPovAlias(DataSrcName, DimName)>>, <<FinancialreportingObjectDescription()>>, and <<Date(“format”)>>.
financial_reporting_object_name
The name of the pdf files. The same parameters as subfolder_name apply.
group_names
The Shared Services group that runs the batch, by row. Not used in the CCRpt example.
role_names
The Shared Services role that runs the batch, by row. Not used in the CCRpt example.
user_names
The Shared Services user name that runs the batch, by row. Not used in the CCRpt example.
email_list
The
SMTP email address that receives the batch pdf output. Although this
is set in the CCRpt example, it does not work because the SMTP
configuration was not done during installation.
external_pdf_root
The root of the file output. This overrides the output from the scheduled batch.
Importing the bursting file to Workspace
For the scheduled batch to read the burst batching file, it must be imported into Workspace.
1) After
creating the batch bursting file in Excel and saving the output as a
comma delimited file, import the file into Workspace by clicking on the
Explore button, navigate to the target folder, and then the menu
File->Import->File and then select the file.
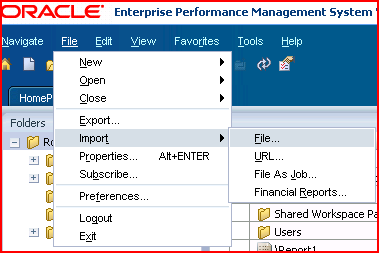 2) Click on Browse and select the file.
2) Click on Browse and select the file. 3) After confirming the file in the File textbox, click on the Next button to move to the Advanced screen.
3) After confirming the file in the File textbox, click on the Next button to move to the Advanced screen. 4) Click on the Next button to move to the Permissions screen.
4) Click on the Next button to move to the Permissions screen. 5) Click on Finish to finish the import process.
5) Click on Finish to finish the import process. 6) The file will appear in the target folder.
6) The file will appear in the target folder. For your amusement, I have stuck a copy of the file here. It’s in (as noted) comma-delimited format.
For your amusement, I have stuck a copy of the file here. It’s in (as noted) comma-delimited format.
Applying the bursting file into the batch scheduler
1) In
the batch scheduler, select the data source, then tick the “Run Batch
for multiple members in the dimension”. Then click on the ellipsis
button to import the burst file.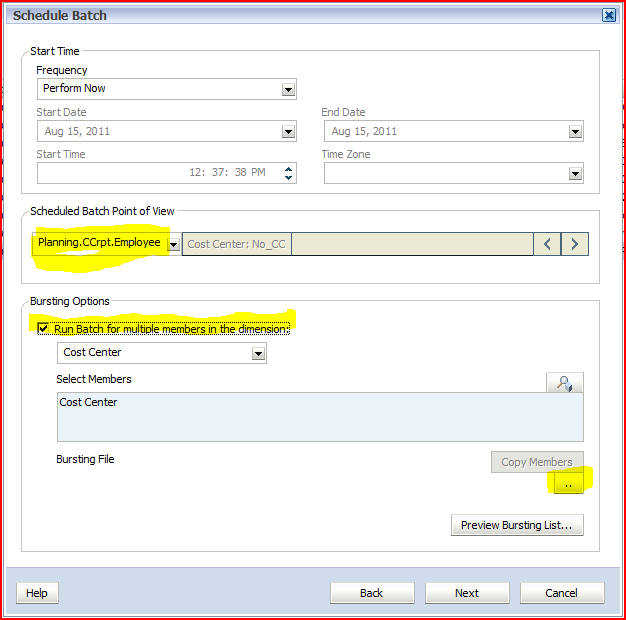 2) Select the burst file – this is the file just imported into Workspace.
2) Select the burst file – this is the file just imported into Workspace. 3) You
will see the comma delimited batch bursting file’s full path. Click on
the “Copy Members” button to apply the values in the batch bursting
file to the data source.
3) You
will see the comma delimited batch bursting file’s full path. Click on
the “Copy Members” button to apply the values in the batch bursting
file to the data source. 4) Once
the Copy Members button has been clicked on, the members in the burst
batch file will be shown in the Select Members text box. This comma
delimited list of members can be modified by clicking on the magnifying
glass.
4) Once
the Copy Members button has been clicked on, the members in the burst
batch file will be shown in the Select Members text box. This comma
delimited list of members can be modified by clicking on the magnifying
glass.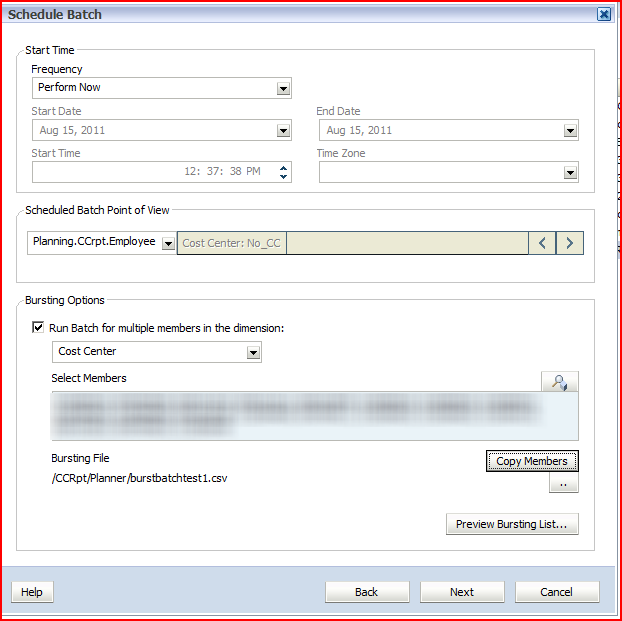 5) Select
the other data source and apply the members by clicking on the “Copy
Members” button. It will look like the members are selected – this is
not the case – never be afraid to click on that button.
5) Select
the other data source and apply the members by clicking on the “Copy
Members” button. It will look like the members are selected – this is
not the case – never be afraid to click on that button. 6) Click on the Next button to continue defining the scheduled batch as defined above.
6) Click on the Next button to continue defining the scheduled batch as defined above.
Conclusion
That was easy, wasn’t it? :)
Okay,
it wasn’t really hard at all, and it is pretty cool functionality.
However, it took me FOREVER and a day to figure out how to do this and I
had to reach out to multiple people (in fact an ex-client from my
ex-consulting company. Hello! Lisa Abrewczynski and Rholanda Brooks)
to get the answer. What, you think I figure all this stuff out by
myself? If only. Oh wait, no one thinks that. Regardless, it was
super nice that they both took time to help me out – I am obliged.
And that’s it! I hope you enjoyed this super short (hah! 25 pages in Word) guide to books, batches, and bursting.
I love it when a plan comes together
No, I am not John “Hannibal” Smith although I will admit to a preternatural
love of the A-Team as a teenager. Ah, youth. What I specifically love
is when one of my rants/diatribes/random collections of
words/occasionally semi-brilliant idea inspires other people. It really
is awesome. And a little scary.
My Spanish buddy (okay, I am stretching a word here, but c’mon, as he is the only person I know in Spain surely he is simultaneously my only-ever-communicated-by-email acquaintance, colleague, BFF, and buddy all at the same time) Francisco Amores Torres had a comment on my Planning security query post.
He wanted to know how to modify the query to show all of the members
in a hierarchical security definition (think inclusive descendants). He
(not me) figured this out using a recursive query. To SQL geeks, this
is like breathing, but for most of us EPM practitioners, it is somewhat
of a challenge. Ooooh, I thought, I want to know how to do that. I inspired him (if an incomplete solution can be thought of as inspiration) and he inspired me. It’s kind of awesome.
Limiting a Planning dimension query
There
are times (I will illustrate a reason why in a few blog posts – this is
too involved to do all at once) when you maybe only want some
of the members in a Planning dimension query and that’s what
Francisco’s query does. You probably can think of some reasons yourself
such as: extracting subsets of dimensions for transfer to other
applications, comparing bits of hierarchies across applications, or even
(hint) using the results of a limited set of members to populate other
queries and limit their scope.
How do you do it?
I
needed a really simple example, so I exercised my Google-fu and came up
with this pretty easy to read and understand (although it is for two
tables instead of one) MSDN article.
One note – this is only possible in SQL Server 2005 and above as CTE (Common Table Expressions) are not in earlier releases.
One other note – in Oracle PL/SQL you use the CONNECT BY clause.
The example
I
am querying just the inclusive descendants of the member alias “USA”
from the Planning sample application. Put in your own anchor to get
other hierarchies. Don’t be scared off by the Table Variable – I just
needed to get the full output of the dimension into a temporary location
so I could use the CTE technique. If I were going to call this code
again and again I’d change that to temporary table and not populate it
after the first pass.
/*
Purpose: Illustrate the querying of all descendants from any member
Modified: 29 July 2012, Cameron Lackpour
Notes: Can only run on SQL Server 2005 and up as it uses Common Table
Expressions (CTE)
- I'm sure this can be done in Oracle but I have to
have some semblance of a life.
*/
/* Set up a Table Variable called @Dimension */
DECLARE @Dimension TABLE (
Parent varchar(80),
Child varchar(80),
Alias varchar(80)
)
/* Populate the Table Variable with the dimension from Planning. */
INSERT INTO @Dimension(Parent, Child, Alias)
SELECT
PO.OBJECT_NAME AS 'Parent',
O.OBJECT_NAME AS 'Child',
-- Use a SQL Subquery to get aliases.
-- NB -- The overall SELECT from HSP_MEMBER ensures that members with
-- and without an alias are selected.
-- ISNULL puts in zero length string in place of NULL
ISNULL((SELECT OA.OBJECT_NAME
FROM HSP_ALIAS A
INNER JOIN HSP_OBJECT OA
ON A.MEMBER_ID = O.OBJECT_ID AND
OA.OBJECT_ID = A.ALIAS_ID), '') AS 'Alias'
FROM HSP_MEMBER M
INNER JOIN HSP_OBJECT O
ON M.MEMBER_ID = O.OBJECT_ID
INNER JOIN HSP_OBJECT PO
ON O.PARENT_ID = PO.OBJECT_ID
INNER JOIN HSP_ENTITY E
ON M.MEMBER_ID = E.ENTITY_ID
-- Entity dimension is ALWAYS DIM_ID 33, but its name
-- can vary, so use the ID
WHERE M.DIM_ID = 33
;
/* Now do a recursive query to get all of the children of a given member's alias. */
WITH MyDimension (CTEParent, CTEChild, CTEAlias, Level)
AS
(
-- Anchor member
SELECT Parent, Child, Alias, 0 AS Level
FROM @Dimension AS d
WHERE Alias = 'USA'
UNION ALL
-- Recursive query
SELECT Parent, Child, Alias, Level + 1
FROM @Dimension as d
INNER JOIN MyDimension AS m
ON d.Parent = m.CTEChild
)
SELECT CTEParent, CTEChild, CTEAlias, Level
FROM MyDimension
And that produces

Just as promised, only the members that are inclusive descendants of USA. Enjoy the hack.
P.S. An alternate way of doing it
I
have an email list (this is pretty common in consulting companies) that
I use to send out various and sundry tips and tricks. Would you
believe it’s called the Stupid Tricks list? You should, ‘cause that’s
what it’s called. Think of the recipients as the brave/unfortunate
souls who get this stuff first; their reaction often determines if I
enlighten/pollute the wider EPM world with whatever idiocy I come up
with.
One of these happy(?) few is fellow Developing Essbase Applications coauthor Gary Crisci. When I sent out this query, Gary pointed out that he had written a blog post called SQL queries for Essbase developers
over a year and a half ago on the same subject but from an Essbase
(really a generic data warehouse) perspective. I encourage you to check
it out as he goes over a slew of different hierarchical queries.
Gary delves into:
- Parent/child Descendants (so similar to the above although not from a Planning perspective)
- Parent/child to Generations
- Parent/child to Levels
- Generations to Parent/child
- Tagging member properties
I really recommend that you check out his blog as there’s good stuff therein.