Where we were or where are we or most importantly where am I?
I have no idea as to the last point but then again I never do. Ever.
Moving on, in the first part of this exciting (surely not but at least useful) series, I related how to stack dimensions in a single column.
Alas and alack, My Man In California, Glenn Schwartzberg, pointed out in the comments to that post that he had already covered this at two different Kscopes. Oh the shame, but as a soon-to-be-ex-board member the number of sessions I get to attend is severely limited. Sorry, Glenn. I had to figure it out on my own. I never do things the easy way. Ever. Again. Bugger.
The Network54 use case I addressed was primarily a need to both stack dimensionality as well as selectively address more or fewer columns of data depending on data scope.
This is quite easily done in a Load Rule, indeed it’s possible in both a SQL as well as text Load Rule and it all centers around how the initial record of a Load Rule. The Stupid Trick here is that if ten data columns are defined at design-time and only five are passed at load time, the Load Rule ignores the last five.
One might think that this would be best accomplished by changing the SQL query within the Load Rule but by doing that one would edit the Load Rule itself, this would be a design-time change , and the number of columns would be modified. I’ll also mention that Load Rules are tricky little buggers that just beg to go FOOM! so I’m loathe to modify them.
Instead, a SQL view that changes the scope of the columns passed to the Load Rule’s SELECT (well, you have to skip the “SELECT” but that’s the action the rule performs) * FROM viewname and ta-da, the Load Rule now selects fewer (or even more with an important caveat) data columns.
That caveat
This more-or-less Load Rule behavior is predicated on the columns that are defined within a SQL view.
I take the point, perhaps even before you’ve raised it, that modifying the SQL is a design-time change. But with these requirements something and somehow is going to change. Load Rule or ALTER VIEW? One man’s meat is another man’s poison so it’s time to pick yours.
What kind of poison for the evening, sir?
I’ll have just a wee slice of SQL:
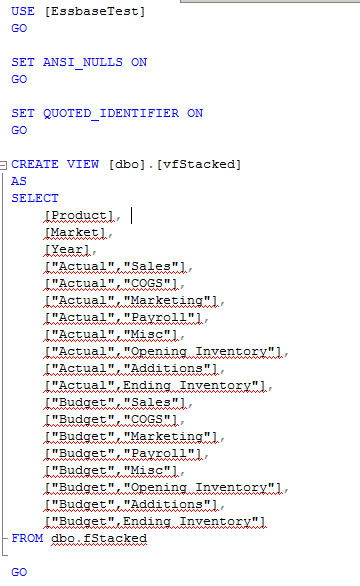
Pulling this in a SQL Load Rule looks like this:
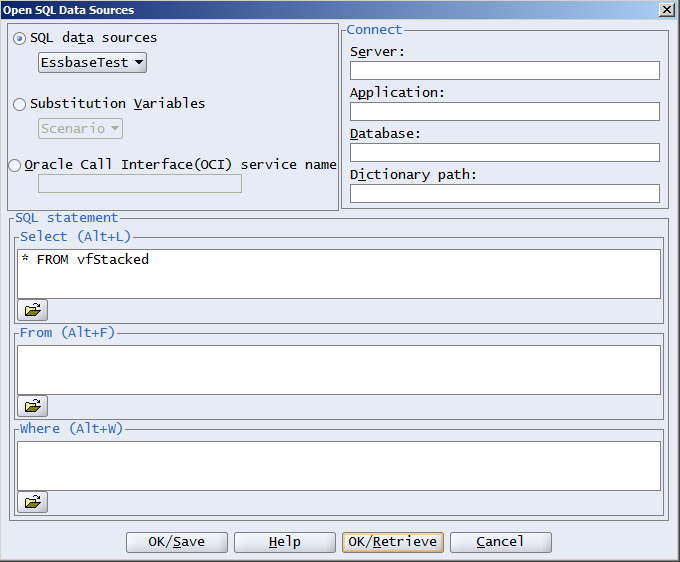
And this:
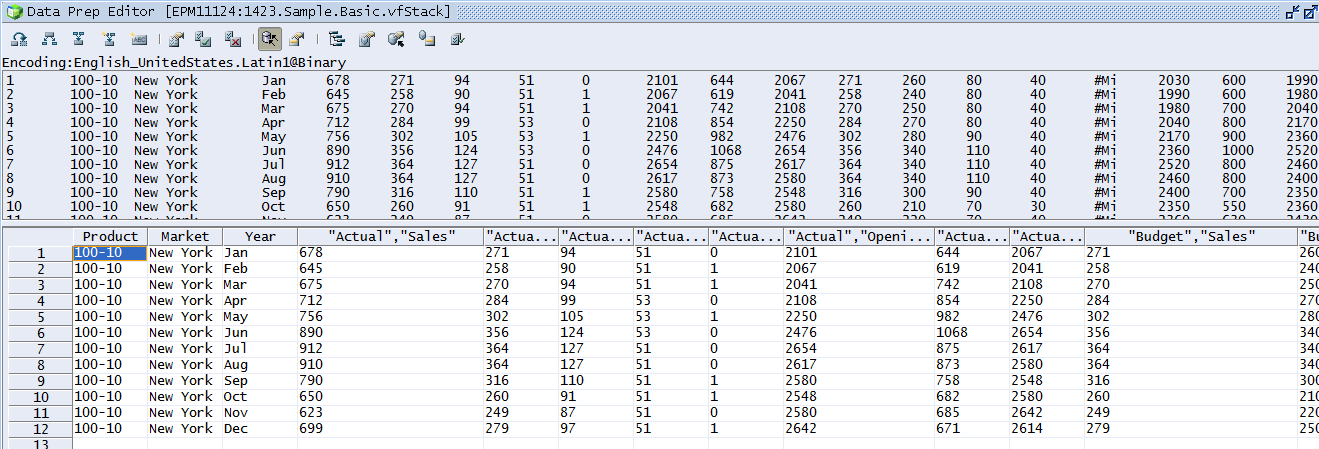
So no different than the original fStacked table which is in turn no surprise given that the fields are the same in the view as they are in the table.
Let’s cut that view down to just Actual columns:
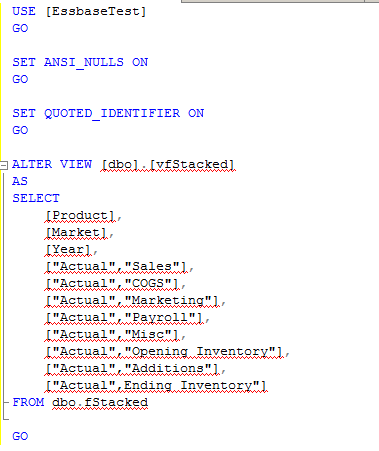
Et voilà!, dynamic Load Rules
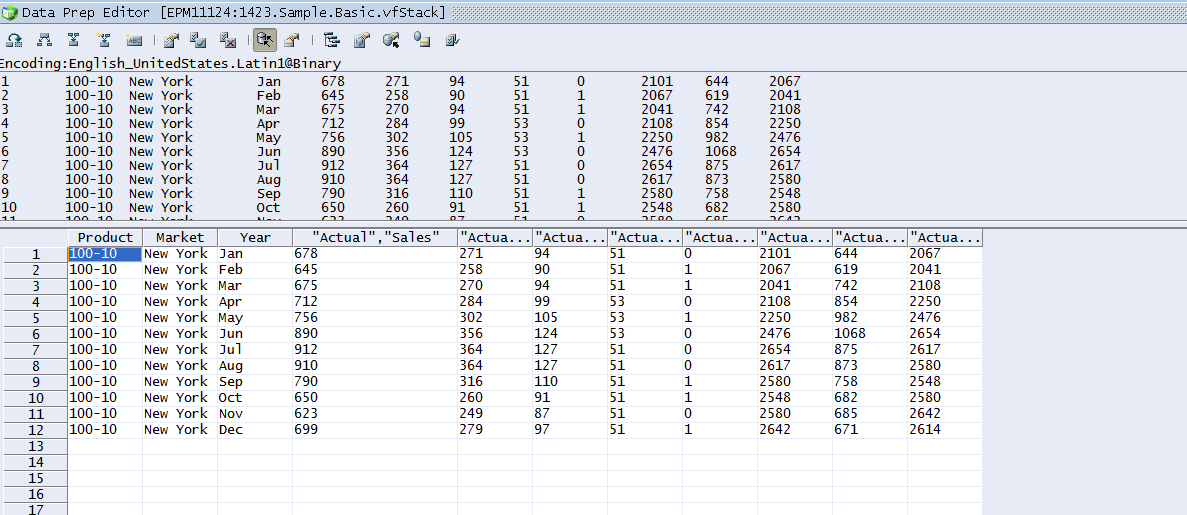
Change the SQL in the view, no change to the rule, change the data columns and thus scope, all with no editing of The Devil’s Own. Gee whiz, could it be that Load Rules aren’t spawn from Old Scratch? Maybe.
Would I do it this way?
Let’s review what this approach does:
- It stacks dimensions in a column, i.e. it allows more than one dimension to be defined for each column of fact data. That’s not a condition of dynamic Load Rules but instead is a requirement of that post way back when in part 1.
- It shows that removing or adding columns to a data source make the Load Rule display more or fewer columns.
The caveat to the above approach is that the definition of the Load Rule’s columns must happen before the data change and the maximum number of possible columns needs to be defined up front.
If this last bit seems odd, think what happens when you load a poorly defined text file such as when you’re told, “There are 13 columns of data,” but in fact there’re really 14 columns 2,312 records down although not in the first 2,311 rows. Whoops, someone forgot to mention that and because the Load Rule defines columns based on its initial 50 row read (yes, you can change this and even the starting position but you’d have to know the exact row to go to) Essbase is going to throw a rod because it doesn’t know how to handle data column 14. The damnable thing of it is if the Load Rule can’t see the column, the Essbase geek can’t add it. The “fix” is to create a one record file that has that 14th column, tag the column as Ignore During Data Load, and for the 2,311 preceding rows it’s as if that column doesn’t exist (remember there is no tab or comma delimiter at the end of those 13 fact field records) until record 2,312. This is the same concept as the “Budget”,”Sales” columns defined when the data exists and then being dropped when the data source no longer contains said columns.
Whew.
So what do I do? Benchmark. I’d benchmark this approach, particularly the full Actual and Budget load example vs. two separate Load Rule streams, one of Actual and the other of Budget. And as this is an ASO cube, I’d kick that latter approach off in multiple MaxL statements writing the contents to a single buffer. Is the performance issue tied to how fast Essbase can commit a temporary tablespace to a permanent one or is it how big the pipe from the fact source is? Dunno till tested.
If a two stream approach worked, there’d need to be some kind of conditional branching in the batch script to decide which or both to load.
Whew, again. No one said that system requirements are easy. That’s why we’re (hopefully) paid the big (even more hopefully) bucks (insert currency of your choice).
Be seeing you.
No comments:
Post a Comment