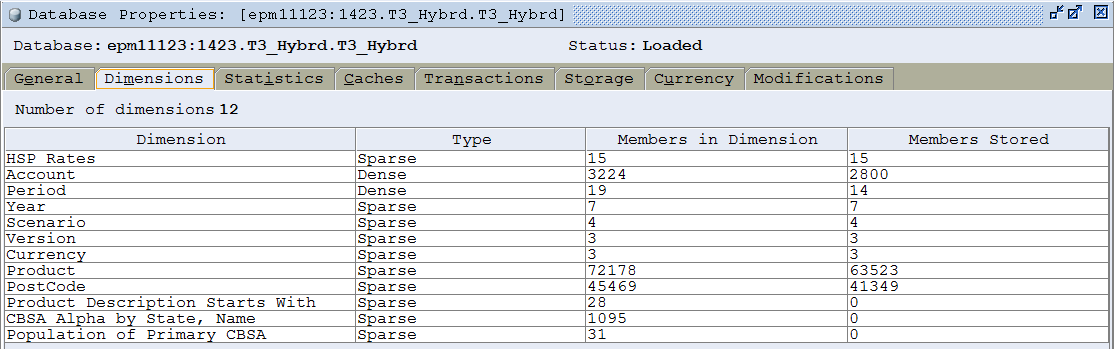
A note before the introduction
MMIC, aka Glenn Schwartzberg, wrote a post on this tool last week. While I would love to identify a vast ACE Director conspiracy because that would mean I was interesting, or a brilliant criminal mastermind, or at least sneaky, alas, the truth is that it is none of these things and instead a figment of my febrile (or is that feeblie?) imagination and the similar subject is simply coincidence. Never fear, Gentle Reader, I have a different take on the tool than Glenn. Whether it is a better or even worthwhile take is of course up to you.
Introduction
I have known Tim Tow, owner of Applied OLAP, since 1995 when he came to my-then employer to teach us the Lex Excel dashboard framework for BI. For those of you old enough to remember Excel 95 (I think that was the release), it came with a sample BI dashboard – I suppose Microsoft thought people would use Excel as a database, calculation engine, and dashboard. Actually, they were spot on and their current desktop BI approach (btw, they jettisoned MDX in MSAS which caused a fair amount of heartburn) continues that philosophy.
Regardless of the Great Enemy’s approach (dear Microsoft Legal, I kid, I kid) twenty years in technology is basically a career and I work today with people who have five years in harness; I should note that I was but a callow IT youth of five years myself when I met Tim. My long friendship with Tim is one of the reasons I am such a fan of his company’s products, including its flagship product, Dodeca, but I am also continually impressed with the free utilities Applied OLAP creates for the EPM community.
Probably the best known tool is the Outline Extractor aka the Next Generation Outline Extractor aka NGOE. Tim took this product over from a skunkworks Hyperion project to get Essbase outlines out to text long ago and shepherded it through its VB API genesis to today’s Java API tool. There have been thousands and thousands of downloads of this product – practically every Essbase practitioner I know has one or more versions of it installed on his server or PC. It really is that useful.
NB – Tim tells me that I am using the first generation of the NGOE and that there is a second version that does not require an installation of the MaxL client. I don’t have that version installed. For those of you that have that release, one of the techniques I illustrate below will be impossible.
A note of thanks
Tim wanted me to note that Harry Gates’ MaxL->file-readable-by-humans utility was the inspiration for creating a MaxL-driven version of the NGOE.
So what’s not to like?
There have been two main complaints about the product: consumption of Essbase ephemeral ports causing OE to timeout and wait for the ports to be freed up and a performance deficit when it comes to large outlines. With the 11.2.3.503 release, that issue of port exhaustion has been resolved, although not documented except by Tim. However, the issue with performance remains with very large databases. One could argue if the outline took a long time to build, it should take a long time to extract, but we are all (or at least most of us and especially me) an impatient lot. What to do?
The pain and not the glory
Let me give you an example with the Hybrid Essbase database Tim German and I created for our Kscope14 presentation on Hybrid. It’s pretty big, at least for a BSO database; I expect to see more and more of these databases as Hybrid becomes common practice. Yes, this is small to middling in an ASO database but bear with me and I will show that even this database tests OE.
For those of you not familiar with the latest and greatest iteration of OE, what I’ll be showing is the GUI interface. Nothing spectacular bit it is very functional and straightforward. Are you using this tool for the latest faux Cloud interface or to get a job done? Thought so.
The example you are about to see is running on my 11.2.3.50sortof500sortof502beta VM. Stay tuned for my exercise in frustration/possible triumph as I install 11.1.2.4 on a new VM in a future blog post, but I digress.
Here I am logging into my VM and selecting the T3_Hybrid.T3_Hybrid database.
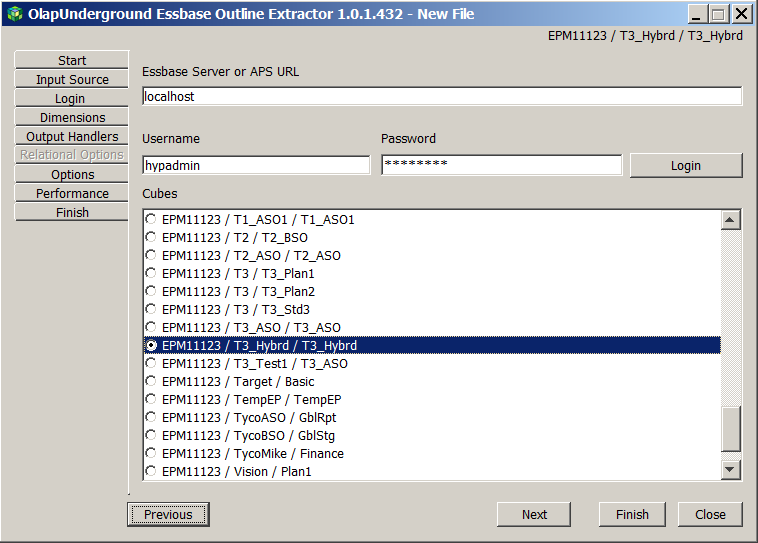
Picking my dimensions – I’m actually not going to select the last two attribute dimensions but am too lazy to retake the shot. So sue me.
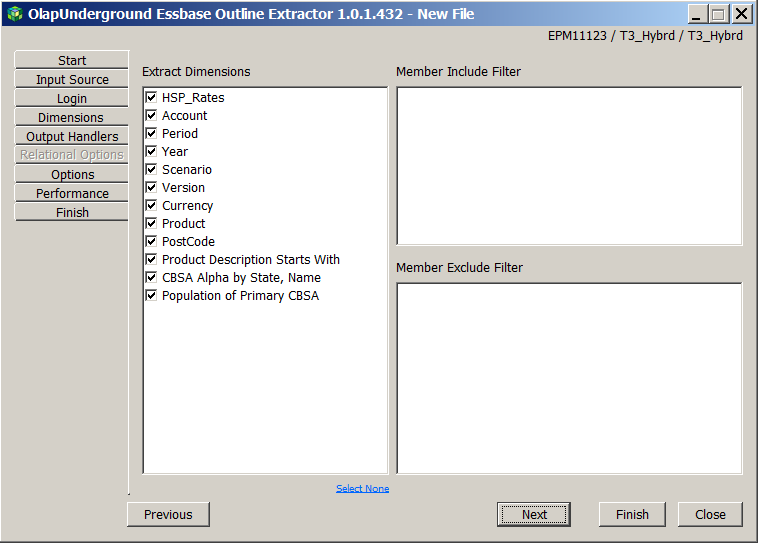
And picking the first (and generally standard) Essbase API selection:

Choosing the Load File format – I think this is the most common of all:

Defining the options. Tsk, tsk, it is better practice to use the | character as a delimiter but I was in a hurry:
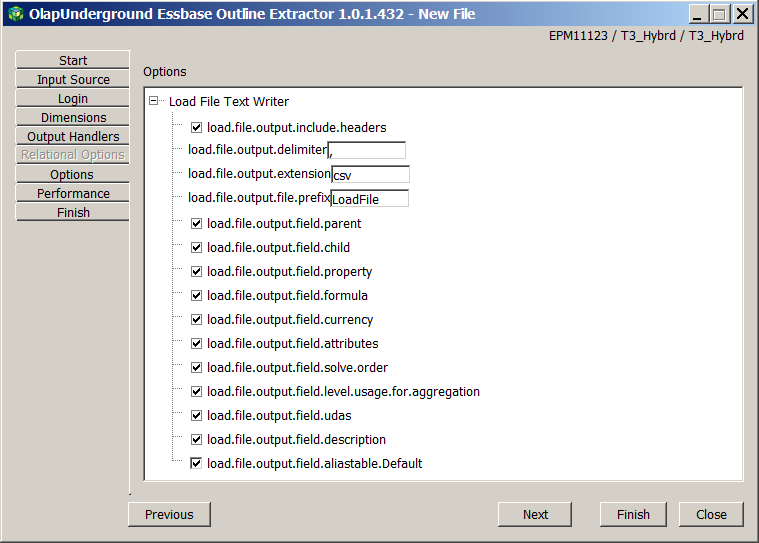
Take the default timeout, which can be troublesome but I am going for bog standard examples:
3, 2, 1 liftoff:
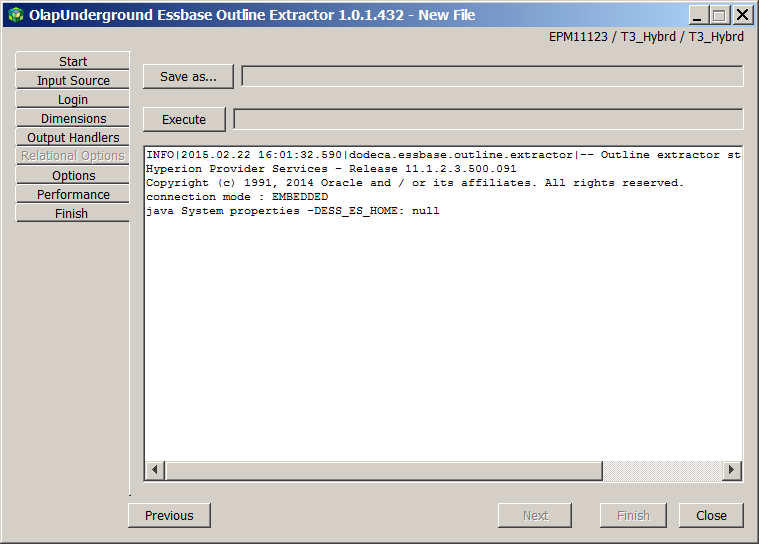
I hit execute, and…go have dinner, exercise, watch some TV, and go to bed only to wake up and find:
For those of you math challenged even more than I, that is 6 ¾ hours from start to finish. The Postcode dimension took almost three hours. Ouch.
This time is acceptable, albeit slow, for the purposes of a blog but can be a real deal breaker when the extracted outline is needed during a work day. It can be even worse, unusable really, when going over a VPN to a client site. Hours to extract a single dimension, and not a very large one at that, are not unheard of. What to do, what to do, what to do.
From the ashes of disaster come the roses of success
I had just such an occurrence recently and I despaired of ever getting the outline extracted. Then it hit me (right between the eyes) that there were three options in the extract that I had never used. Why, why, why? Laziness, or a lack of imagination, or most like stupidity is the answer. Am I being hard on myself? Read on, Gentle Reader, and I suspect you will find yourself in agreement.
With the self-flagellation out of the way, what are those Paths Not Taken? Why it’s good old MaxL. I am somewhat familiar with the MaxL outline extract output – it is in XML format and unless you are uncannily good at reading XML, it requires a parser to something mere humans can readily comprehend. Do you suppose that OE has just such a parser? Could be, rabbit.
Let’s first let OE run the MaxL extraction:
Don’t try this at home folks
Running the OE MaxL extractor without the correct pathing to MaxL provides this lovely Java stack dump:
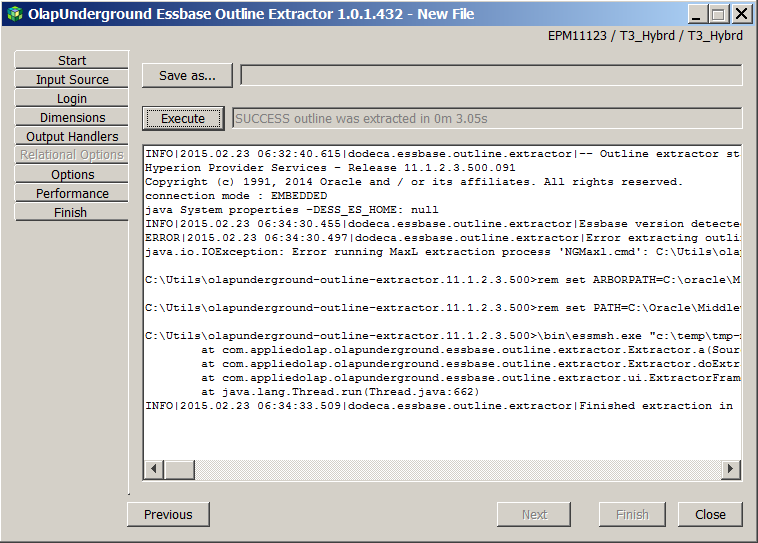
The product does provide a hint – NGMaxl.cmd died. Why? OE cannot find essmsh.exe. This is an easy fix – go find the NGMaxL.cmd file and look for the “set ESSBASEPATH” line – it will be commented out and defaults to the C: drive; in my case this was fine as I am running on a simple VM – you may need to change this depending on your install.
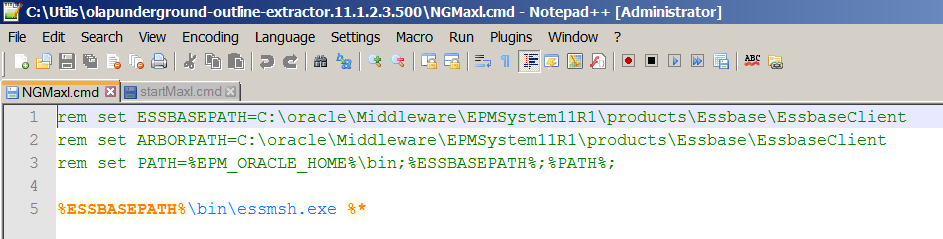
Uncomment (or in my case, copy and leave the commented line alone because I am chicken) and verify that indeed essmesh.exe is where the ESSBASEPATH variable points:
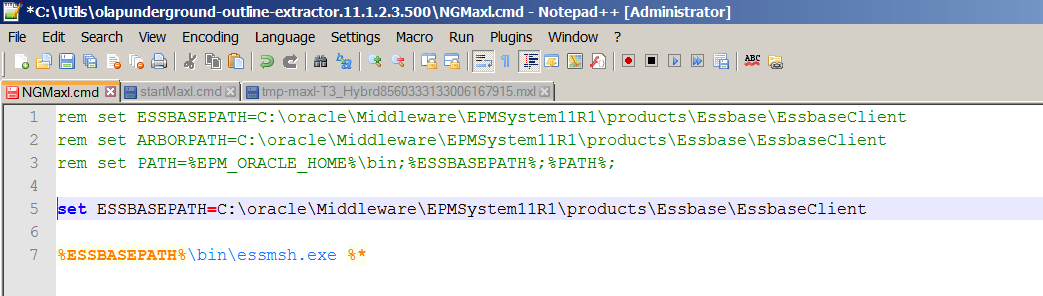
The sweet smell of success
Run the process again, picking the same options and we see that the outline extract ran in 9.54 seconds. Whaaaaat?
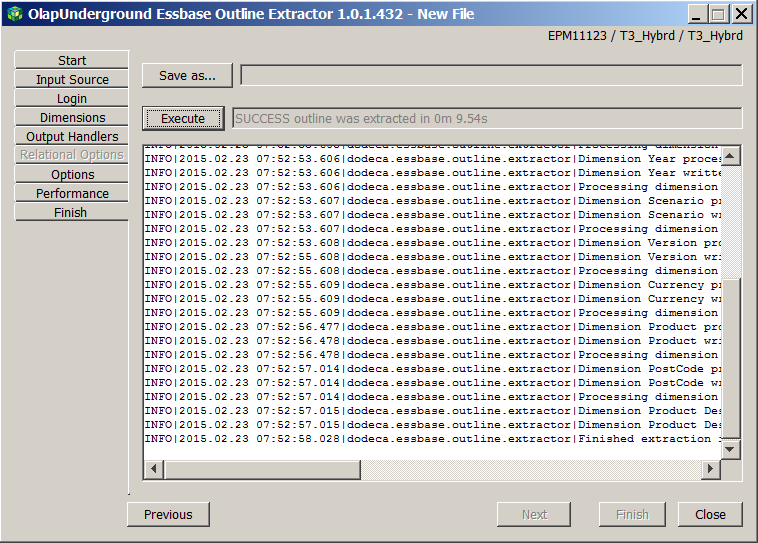
The proof is in the pudding, and I love that sweet at the end of a meal
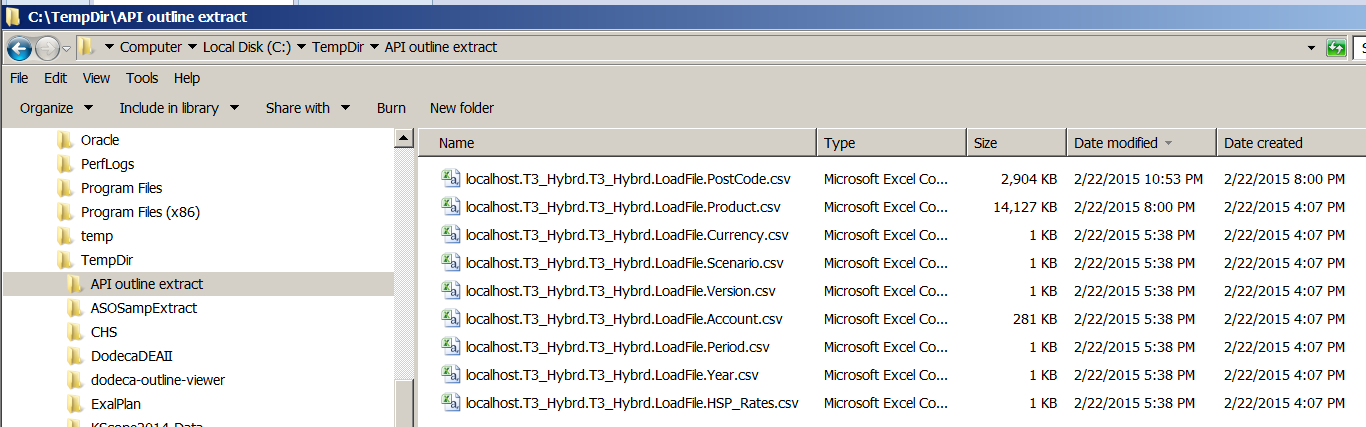
That export process is so fast, it is frankly unbelievable. Looking at the times in Explorer shows it starting at 8:16 and finishing within the same minute. Given that the process took less than 10 seconds one can hardly characterize that as surprising.

One of these things is not like the other, one of these things does not belong
Hmm, the file size for some of the dimensions are a wee bit different. Could the MaxL approach have incorrectly or incompletely extracted dimensionality?
The Essbase API:
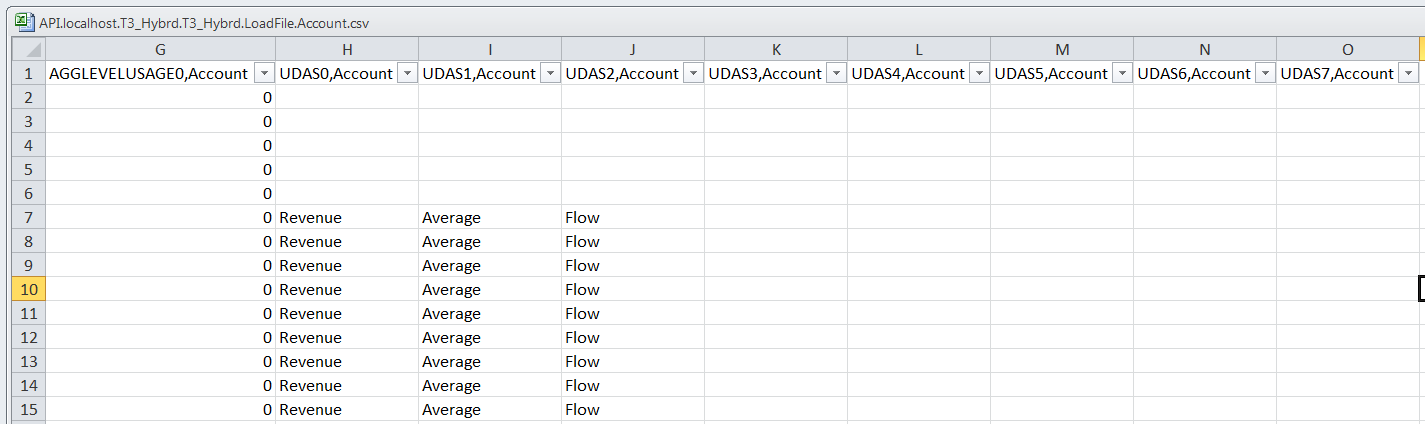
Or, if you prefer in text format:

MaxL:
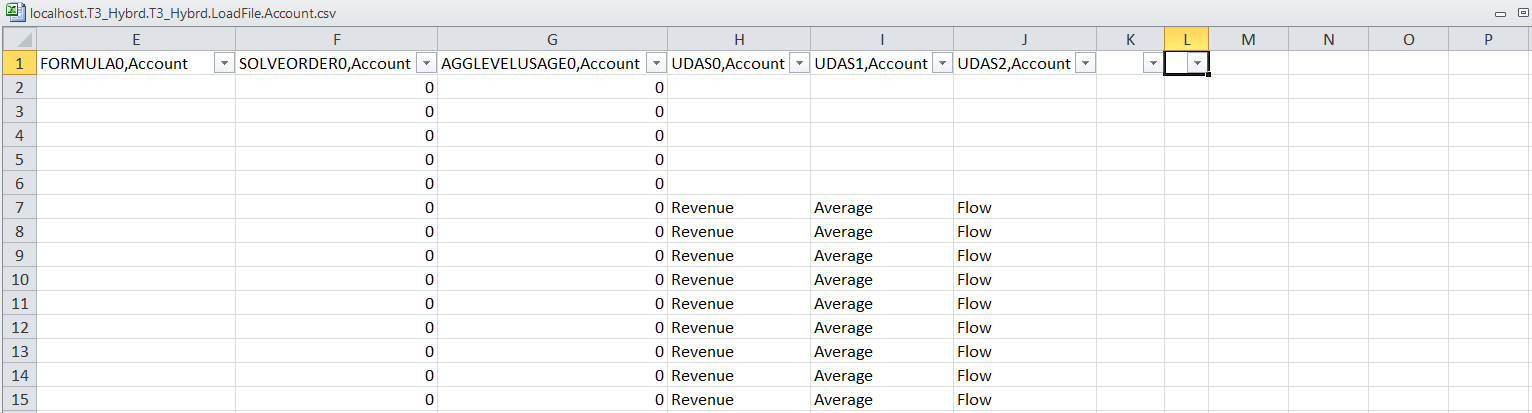
Again, in text:

The only difference is the number of UDAs. Is this a problem? If you look at the two screenshots, you will note that the API approach has extra columns for UDAs which happen to be blank other than the header. Yes, yr. obt. svt. could not believe his eyes and double checked. Nope, nothing there.
So why the extra columns? It turns out that these are UDAs assigned to the dimension but not actually assigned to any member. In essence the member information is exactly the same – the slight difference in header is responsible for the difference size.
Wowza!
One other note: in this Network54 thread, there was a comment that the MaxL approach does not capture solve order. I’m here to tell you that in fact the MaxL export references both solve order and levels considered for aggregation.
Try this on for size
If the OE can run MaxL, surely I can too right from the MaxL shell. What kind of MaxL grammar should I use? Well, I could go off and look at the Tech Ref, or I could just steal the existing MaxL that the OE created. As noted, I am lazy (as all good programmers are, although in this case it is a different, Not Good, kind of laziness on my part) and so I eschew rewriting something already done.
Take a look in your TEMP folder and search for a file with a .mxl extension. Yep, there it is in all of its MaxL glory.

And now replicate in the MaxL shell. You would think, given that I am copying someone else’s code, that I could get it right. But noooooo:
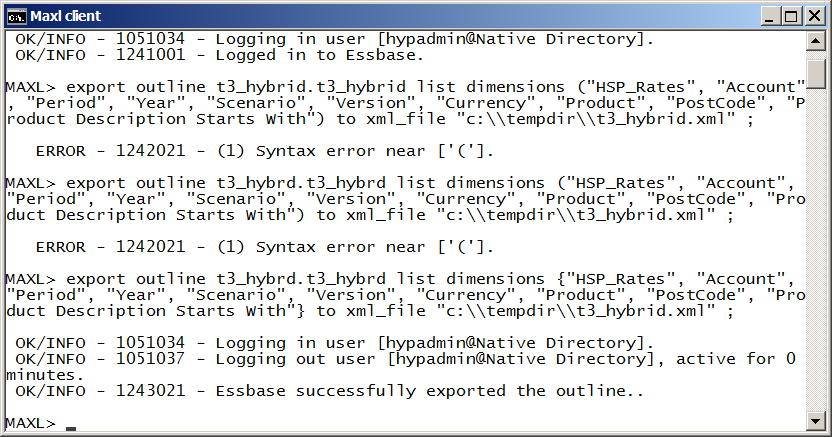
I do eventually get it right. See, I show you my Ultra Super Bad Typing Skills – there are no coding secrets on this blog.
Note that as with the API approach, I am not extracting all of the dimensions, hence the list dimensions syntax.
I eventually got it right. Again, so fast that MaxL doesn’t even log it. But did it work? Oh yes:
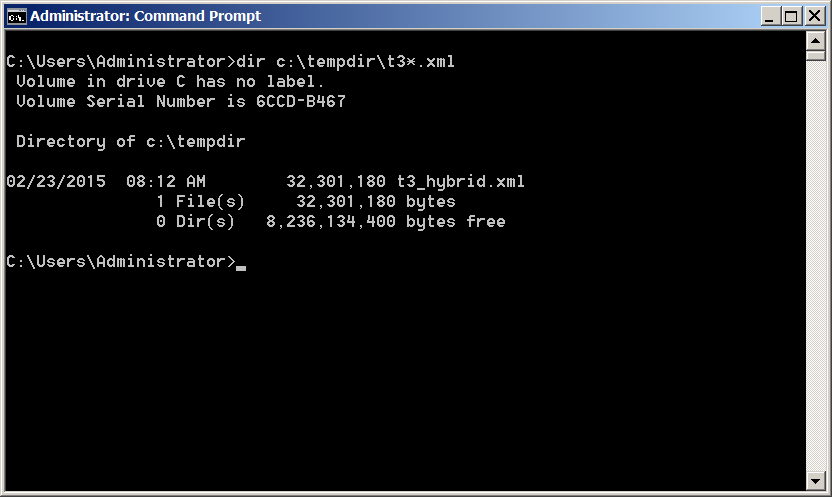
Wow, a 32 MB xml file. Who would want to read this? Happily for all of us, or at least me, I can use OE’s XML outline parser to read in the file and spit out
This time, I will use the manually extracted outline XML file:
And run the extraction:
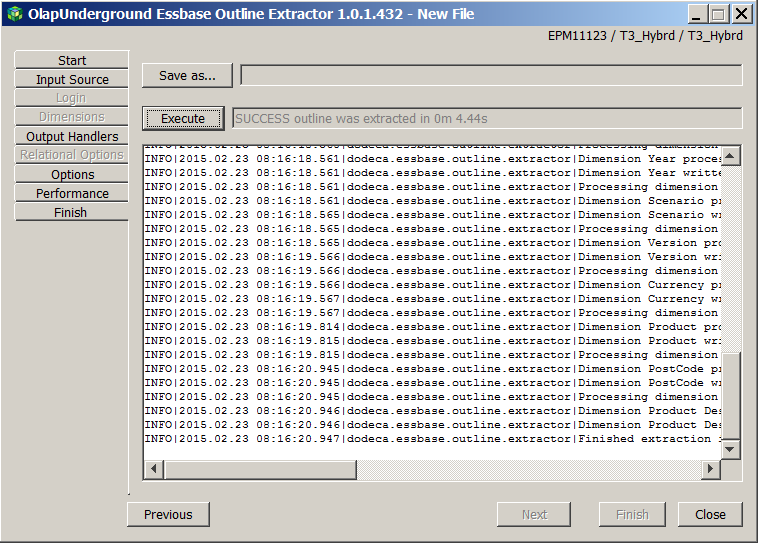
This is pretty good – I have almost halved the time. Of course we are considering this within the context of a 10 second OE-only approach and of course there was my manual extraction via the MaxL shell, but still, that is some pretty amazing performance. Less Than Five Seconds. Phowar.
The numbers
The numbers are a bit unbelievable but you can do the math if you don’t believe me:
Time in seconds
|
X faster
|
Var % to API
| |
Essbase API
|
24300
|
0.00
|
0.0000%
|
OE MaxL
|
9.54
|
2,547.17
|
99.9607%
|
Cameron MaxL
|
4.44
|
5,472.97
|
99.9817%
|
You read that right – 2500 (twenty five hundred or two thousand five hundred) times as fast as the API. Who knew? And why would anyone ever, ever, ever use anything else? Beats me.
I am sandbagging this one a bit as it does not count the time to extract the data from the MaxL shell but the numbers are all kinds of amazing and awesome. But still.
It took you this long, Cameron? Why?
Sigh. I wish I knew. I really, really, really wish I knew. As I wrote above, mental sloth is likely the root cause. Hopefully you are smarter than I and already knew all of the above. I only wrote this because I wanted to save other, misguided, Essbase hackers.
This approach makes the OE moar bettah, much moar bettah, than before, and it was already pretty awesome. Henceforth, I shall look askance at the API extract. I really cannot think of a reason to use it. I am sure the Best and Brightest will correct me on that but for the time being, that is my position.
Thanks again Tim, and the rest of the crew at Applied OLAP, for making such a fantastic product and thanks doubly for providing such a fast, fast, fast way to extract the dimensionality.
Be seeing you.
2 comments:
Thanks for this post. I am one of those Essbase hackers who tend to stick with the first option given and thus would never discover this until I read your post.
I'd like to share one observation. I ended up writing my own Maxl script to export the outline and used OE to parse the extract. It worked beautifully until it didn't. At some point, OE kept giving me an error saying "Java heap size" when I tried parsing the otl extract. After much painful search, I realized that my Maxl export was statement was missing the word 'tree'. The weird thing is that, without 'tree', the statement still ran fine and gave no error. I was fooled into thinking my Maxl (or typing) was good when it was not. The telltale signs were (1) the otl extract was unusually large (240Mb vs the correct size of 6Mb) and (2) OE skipped some of the steps.
One more thought. The Essbase API is a good choice if (1) the dimension is small; (2) if one wants to get only certain part of the hierarchy (versus Maxl always exports the entire dimension).
Hi,
I am struggling to extract the outline to excel format. tried OLAP Underground and Export outline (Maxl script) and got the output but all showing the outline as per generation reference.
I would like to view the Outline as per the Level reference, is there a way ...!
Post a Comment