Introduction
I am so sad/pathetic/a-geek-desperately-in-need-of-a-life. No, that is not the point of this blog post (although the statement is true) but instead it is an observation that I am an inveterate hacker who just cannot leave a potentially good hack alone.
What do I mean by that?
At Kscope13 (alas, sadly passed but wow it was fun) this past week (a bit of a time issue here as I started writing this whilst flying home on the plane – ooh, technology, and sadness but what else am I going to do with myself?) I sat in on a BSO optimization panel. My hated and despised former oppressor beloved former employer, Edward Roske, mentioned the subject of data extracts and also that he found Essbase Report Scripts to be faster than MDX for exporting data. This intrigued me (actually, I think my eyebrows went over my hairline, round the top of head, and down my neck) because that is not exactly the result I saw in my testing here. OTOH, Edward doesn’t drop hints like this unless he is pretty sure of what he says and thus it behooves me to give it a try and see what happens.
Edit -- Edward also mentioned that he used a report script keyword called {SSFORMAT} as part of his data extraction approach. This was even more intriguing because I’ve never heard of it and I have been using report scripts for an awfully long time. What oh what oh what is he going on about?
What I’m going to try to do with this post
While I started this blog entry out as a test to try to measure the impact of {SSFORMAT} on report script data extraction of course went my inquiries went off the rails as they are wont to do and I found myself measuring the much more interesting overall performance question (and I think what Edward was really alluding to): What is the fastest Essbase data extraction to disk method? As seemingly always with Essbase, “It depends”, but this blog post will attempt to qualify what the dependencies are and which approach is best for your data extraction needs.
Why this got so interesting so fast
I think one thing I’ve learnt from participating in an Exalytics benchmarking test (which was more like a treatise on how maybe not to perform a benchmark) is to try to have a variety of test cases. And that turned out to be really important in this example because I soon found that the time Essbase takes to extract data is only one part of the performance puzzle. There is also the not so little issue of how long Essbase/MaxL/whatever takes to write that information to disk. Do not underestimate this component of performance because if you do, you will be guilty of the same mistake that I made, i.e., thinking that the time shown in the application log for a particular action is equivalent to the actual time for a data extraction process ‘cause it ain’t necessarily so.
The first question (and the obvious one if you solely look at the logs) is which tool has faster Essbase performance? Report scripts or MDX? With or without {SSFORMAT} if a report script? What makes {SSFORMAT} faster if it is indeed faster? Can other techniques using report scripts have equivalent speed? Is {SSFORMAT} any use at all?
And then (once you the tester have noted some weirdo results) in elapsed time is which tool has faster overall (command issued to output complete on disk) performance – report scripts or MDX?
Whew, what a lot of questions. I guess I am just a benchmarking fool because I try to answer these with databases you can (mostly) replicate/improve/totally prove me wrong with.
What do I mean by all of this? Simply that the Essbase application log lies. Sometimes.
NB – I do a little bit with the BSO calc script language DATAEXPORT but as I am going to spend time bouncing between BSO and ASO I will pretty much be ignoring that approach. There are some numbers in the last test suite for your edification.
The truth
The Essbase report script time is 100% accurate – if it takes 25 seconds to write a report script out to disk, it took 25 seconds from the time of issuing the command to the time that you can edit the file in a text editor. So truth, justice, and the American way.
{SSFORMAT}
So what about {SSFORMAT}? Does it really make any difference? Edward mentioned it was undocumented (so how did he know?) but actually it can be found in official Oracle documentation. So not mentioned but shown in code samples.
Of course, once I heard this I simply had to try it out to see what it does. And also of course, as it is an undocumented (mostly) keyword I didn’t really know what it could or should do. From a bit of testing I can relate that the command:
- Removes page breaks and headers aka { SUPHEADING }
- Uses tab delimits aka { TABDELIMIT }
- Rounds to zero decimal points aka { DECIMAL 0 }
- Is supposed to make reporting fast, fast, fast
Is it really the case that {SSFORMAT} makes extracts faster? Is Edward right or not?
A mangled <DIMBOTTOM report
I took the Bottom.rep report script that comes with every copy of Essbase and Sample.Basic, modified it to write lots and lots of rows, and came up with the following report. Yes, it is kind of ugly, but it generates 133,266 rows when not using {SSFORMAT} – not exactly a big report but something that will hopefully register in the Sample application log.
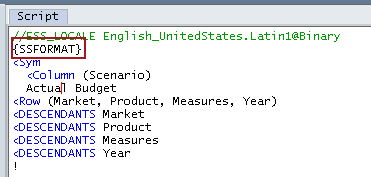
Without SSFORMAT

Looking at this report, we can see column headers, space delmiting, and (although you can’t see it, I can) page breaks.
Total retrieval time? 1.172 seconds.
With SSFORMAT
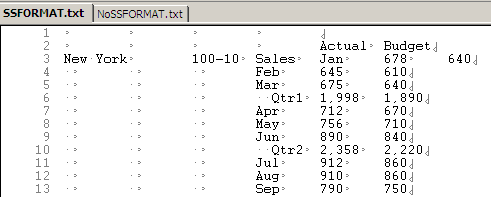
The row count is now 120,962 rows. The data is the same, but the header is suppressed so fewer rows.
Total retrieval time? 0.906 seconds. That’s almost a quarter faster – 22.7%. So in the case of this database at least, Edward is right.
And why is he right? He’s right because {SSFORMAT} gets rid of stuff. Stuff like spaces and headers, in other words, it’s making the file smaller and smaller = faster. At least in this case.
But Sample.Basic is not exactly anyone’s description of the real world. What about another sample database?
Enter ASOsamp.Sample
Just like Sample.Basic, it is sort of difficult to argue that this database is totally reflective of much of anything in the real world as it is a pretty small database in ASO terms. Regardless, you too can run these tests if you are so inclined and it is at least a little more realistic than Sample.Basic.
Test cases
I came up with a bunch of different report scripts to try to see if I could duplicate what I saw in Sample.Basic and also if I could come up with a way of duplicating {SSFORMAT} or realize that there was some magic in that command. Is there?
Here’s the base report for all tests except the last two.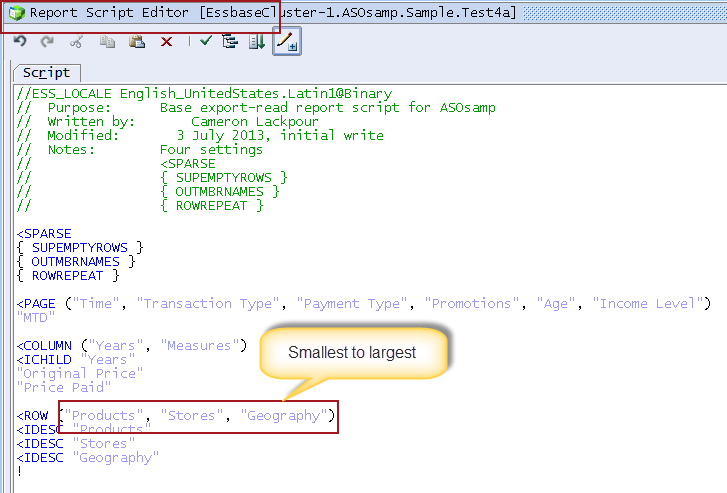
Note the order of the dimensions on the rows. This will become important later. This is (thanks, Natalie Delamar for finding the link) ASO good practice. Except that it isn’t, at least sometimes. Read on, gentle reader.
The test case basically takes the above report and modifies, a bit, how the data gets exported.
Name
|
Details
|
Test4a
|
Base report with missing rows suppressed, member names, repeated rows, smallest to largest on rows
|
Test4b
|
As Test4a with tab delimit, decimal 0, suppress headings
|
Test4c
|
As Test4a with SSFORMAT
|
Test4d
|
As Test4a with decimal 16, suppress headings
|
Test4e
|
As Test4d, with SSFORMAT
|
Test4f
|
As Test4d, largest to smallest on rows
|
I set up a simple MaxL script with the timestamp keyword to get the true export time.
The Essbase Report Script code
spool on to "c:\\tempdir\\Report_script_query_ASOsamp.log" ;
login XXX XXXX on XXXX ;
alter application ASOsamp clear logfile ;
set timestamp on ;
export database ASOsamp.sample using server report_file "Test4a" to data_file "c:\\tempdir\\Test4a.txt" ;
export database ASOsamp.sample using server report_file "Test4b" to data_file "c:\\tempdir\\Test4b.txt" ;
export database ASOsamp.sample using server report_file "Test4c" to data_file "c:\\tempdir\\Test4c.txt" ;
export database ASOsamp.sample using server report_file "Test4d" to data_file "c:\\tempdir\\Test4d.txt" ;
export database ASOsamp.sample using server report_file "Test4e" to data_file "c:\\tempdir\\Test4e.txt" ;
export database ASOsamp.sample using server report_file "Test4f" to data_file "c:\\tempdir\\Test4f.txt" ;
export database ASOsamp.sample using server report_file "Test4g" to data_file "c:\\tempdir\\Test4g.txt" ;
export database ASOsamp.sample using server report_file "Test4h" to data_file "c:\\tempdir\\Test4h.txt" ;
exit ;
I can use the times that MaxL throws into the log file to figure out exactly how long the export process really takes.
Export results
Name
|
"Essbase time" in seconds
|
File size in bytes
|
# of rows
|
Start time
|
End time
|
Elapsed time in seconds
|
Test4a
|
48.429
|
201,033,651
|
1,475,017
|
13:17:03
|
13:17:52
|
49
|
Test4b
|
47.337
|
137,485,186
|
1,316,166
|
13:17:52
|
13:18:39
|
47
|
Test4c
|
46.541
|
137,485,443
|
1,316,169
|
13:18:39
|
13:19:26
|
47
|
Test4d
|
50.431
|
306,891,743
|
1,316,166
|
13:19:26
|
13:20:16
|
50
|
Test4e
|
49.978
|
306,892,000
|
1,316,169
|
13:20:16
|
13:21:06
|
50
|
Test4f
|
41.633
|
306,891,743
|
1,316,166
|
13:21:06
|
13:21:48
|
42
|
Hmm, that “It depends” comment is rearing its head again, isn’t it? There’s barely any difference between the tests. The difference that I saw with Sample.Basic might be an anomaly or (probably more likely) it might just be too small of a database to measure much of anything.
So in this case at least, Edward is wrong – {SSFORMAT} has no measurable impact, at least on ASOsamp. And even file size has no real impact. Weird.
There is one thing that doesn’t make a ton of sense – take a look at that last test, Test4f. It does something that, in theory, ASO Essbase is supposed to hate – largest to smallest dimensions on the rows.
And that’s what provided better performance, even with 16 decimal points. So is that post from 2009 wrong?
A brief side trip into proving an adage
So is that Essbase Labs blog post right, or wrong? Only one way to know.
Name
|
Details
|
Test4g
|
Decimal 0, largest to smallest on ROWs, just about all dimensions
|
Test4h
|
Decimal 0, smallest to largest on ROWs, just about all dimensions
|
Name
|
"Essbase time" in seconds
|
File size in bytes
|
# of rows
|
Start time
|
End time
|
Elapsed time in seconds
|
Test4g
|
59.099
|
204,609,652
|
1,316,166
|
13:21:48
|
13:22:47
|
59
|
Test4h
|
197.411
|
204,609,652
|
1,316,166
|
13:22:47
|
13:26:04
|
197
|
Here’s the code with smallest to largest on the row:
So this is interesting. Sometimes, organizing the report from smallest to largest, as in the above Test4g results in much faster performance.
And sometimes as in Test4f (which, to be fair is not a complete orientation of dimensions to the row), largest to smallest is faster.
I hope you all know what I am about to write about which approach is right for your report: It depends.
But what about MDX?
Indeed, what about it? The output formatting that comes out of MaxL via MDX in a word, stinks. But who cares if it stinks if it’s fast, fast, fast. Of course it has to be fast to be worthwhile. So is it?
The test cases and the code
MDX doesn’t really have an output command the way a report script does – it can’t be part of an export database command in MaxL. Instead, one must run it via a shell. Happily (or not, as you will see in a moment), MaxL can be that shell.
I wanted to mimic the report script code as closely as I could. Of course I can’t use {SSFORMAT} but I can certainly try to test how long these queries run for and what happens when I write more or less data to disk. I added or removed content from the output files by increasing/decreasing column width, decimals, and the non-specified POV dimensions on the row or not.
Test cases
Name
|
Details
|
MDX1
|
2 decimals, 40 wide, dims on row
|
MDX2
|
As MDX1, no dims on row
|
MDX3
|
As MDX1, 80 wid
|
MDX4
|
As MDX2, 80 wid
|
MDX5
|
16 decimals, 40 wide, dims on row
|
MDX6
|
As MDX4, no dims on row
|
MDX7
|
As MDX5, 80 wide
|
MDX8
|
As MDX5, 80 wide
|
Sample code
To give you a feel for the code, here’s the basic query with POV dimensions on the row.
SELECT
{ CrossJoin ( { [Years].Children }, { [Measures].[Original Price] } ) }
ON COLUMNS,
NON EMPTY CrossJoin ( { Descendants( [Products] ) } ,CrossJoin ( { Descendants( [Stores] ) }, { Descendants ( [Geography] ) } ) )
ON ROWS,
CrossJoin ( CrossJoin ( CrossJoin( CrossJoin ( {[Transaction Type]}, {[Payment Type]} ), {[Promotions]} ), {[Age]} ), {[Income Level]} ) ON PAGES
FROM [ASOsamp].[Sample]
WHERE ([Time].[MTD]) ;
Sample output
So is MDX quicker than a report script?
Name
|
"Essbase time" in seconds
|
File size in bytes
|
# of rows
|
Start time
|
End time
|
Elapsed time in seconds
|
MDX1
|
9.789
|
318,513,488
|
1,316,184
|
9:18:01
|
9:24:47
|
406
|
MDX2
|
9.701
|
265,867,452
|
1,316,187
|
10:18:49
|
10:25:30
|
401
|
MDX3
|
9.802
|
634,394,487
|
1,316,188
|
8:31:13
|
8:41:23
|
610
|
MDX4
|
9.688
|
529,101,199
|
1,316,187
|
8:12:52
|
8:21:30
|
518
|
MDX5
|
9.76
|
318,514,116
|
1,316,185
|
10:59:35
|
11:15:45
|
970
|
MDX6
|
9.716
|
265,867,401
|
1,316,187
|
10:33:16
|
10:45:26
|
730
|
MDX7
|
9.774
|
634,394,436
|
1,316,188
|
11:26:09
|
11:41:57
|
948
|
MDX8
|
9.729
|
529,101,001
|
1,316,187
|
11:50:58
|
12:03:32
|
754
|
Yes and no, all at the same time. Yes, the Essbase time as logged in the ASOsamp.log file is much, much quicker than a report script. But the overall time (again from the timestamp command in MaxL) is slower. A lot slower. MaxL is not particularly good at writing data out. It’s single threaded and writing out half a gigabyte text files is quite arguably not really what MaxL is supposed to do. And it agrees.
Of course if one could grab that output via MDX and write it out more quickly, the MDX would be the fastest retrieve method bar none, but that simply isn’t an option in a simple scripting test. I can’t say I know what Perl or the API or some other method might do with this kind of query. Any takers on testing this out and pushing the Envelope of Essbase Knowledge?
For the record, Edward is right, report scripts beat MDX as an extraction process. Or do they?
One last test
I have to say I was a bit stumped when I saw the above results. Edward was right? Really? Against all of the testing I had done on that Really Big BSO database with report scripts, DATAEXPORT, MDX NON EMPTY, and MDX NONEMPTYBLOCK? Really? Time to run the tests again.
I’m not going to go through all of the tests as they are in that post, but here are the tests and the results (and note that I believe I goofed on that old post, report scripts are 10x as bad as I measured before. Whoops) for your perusal.
The tests
Name
|
Details
|
ExalPlan_RS1
|
Extract of allocated data with 16 decimals, tab delimit, member names, repeated rows, missing rows suppressed
|
ExalPlan_RS2
|
Same report script layout as ExalPlan_RS1, but {SSFORMAT} and SUPEMPTYROWS only
|
ExalPlanCalc
|
Essbase BSO calc script using DATAEXPORT
|
ExalPlan_MDX1
|
Same layout as report scripts, uses NON EMPTY keyword
|
ExalPlan_MDX2
|
Same as MDX1, but uses NONEMPTYBLOCK
|
The results
Name
|
"Essbase time" in seconds
|
File size in bytes
|
# of rows
|
Start time
|
End time
|
Elapsed time in seconds
|
ExalPlan_RS1
|
13,392.3
|
1,788,728
|
21,513
|
15:40:52
|
19:24:04
|
13,392
|
ExalPlan_RS2
|
13,068.7
|
1,243,630
|
21,513
|
19:24:04
|
23:01:53
|
13,069
|
ExalPlan_Calc
|
947.842
|
2,548,818
|
21,512
|
23:01:53
|
23:17:41
|
948
|
ExalPlan_MDX1
|
640.562
|
3,485,581
|
21,522
|
23:17:41
|
23:28:24
|
643
|
ExalPlan_MDX2
|
1.515
|
3,536,291
|
21,835
|
23:28:24
|
23:28:29
|
5
|
So in this case, Edward is wrong. MDX trumps report scripts. I think maybe, just maybe, he’s human and is sometimes right, and sometimes wrong.
What’s going on?
What an awful lot of tests – what does it all prove?
I think I can safely say that {SSFORMAT} doesn’t really make much of a difference, at least with the report that I wrote for ASOsamp. Maybe in other reports, like the one I wrote for Sample.Basic, it does. Maybe not. You will have to try it for yourself.
Think about what {SSFORMAT} will do to the output – especially the zero decimal points (and implicit rounding). Is that what you want? If yes, then it is a quick and dirty way to get rid of headers and tab delimit. Other than that, I can’t say I see any real value in it.
The current score (Edward and I are not really in any kind of competition, but this is a handy way to figure out who is right and who is wrong, or righter or wronger, or…well, you get the idea): Edward 0, Cameron 1.
Now as to the question of report script vs. MDX I think the question becomes a lot murkier. In some cases, especially extracts that seem to go export many rows of data, report scripts, at least with the reports and MDX queries I wrote against ASOsamp, report scripts are significantly faster than MDX.
The score has changed to Edward 1, Cameron 1. A dead heat.
But what about queries that go after lots and lots and lots of data (think really big databases) and only output a relatively small amount of rows? Then MDX, at least in the case of a ridiculously large BSO database, is faster.
One could argue Edward 1, Cameron 2, but honestly, it’s a pretty weak point.
What does all mean for you? Wait for it...
It depends.
In other words, just like seemingly every Essbase truism out there, you must think about what you are trying to do and then try different approaches. I wish, wish, wish I could make a blanket statement and say, “Report scripts are faster” or “MDX queries are faster” but it simply isn’t so.
I will say that if I could get MDX output into something other than MaxL, I think MDX would beat report scripts each and every time. But I have spent waaaaay more time on this than I expected and maybe if I can get a Certain Third Party Tool to play along, I can prove or disprove this hypotheses. Or maybe someone else would take the output from MDX via the JAPI and throw it against a text file. In any case, MaxL’s single threaded nature on log output (which is how MDX writes to disk) is slow, slow, slow.
I have to stop listening to that guy – the above is two full days of testing and coding to try to see if he was full of beans or not. And in the end the results were…inconclusive. Such is life.
This blog post brought to you by the John A. Booth Foundation for Impecunious Independent Consultants
No, I am not crying poverty, but know that the times and tests are because of the generosity of John who is allowing me to use one of his slower servers (yes, servers, and yes, it is very nice that he is willing to share it with me, and yes, it is kind of odd that he owns several real honest-to-goodness Essbase servers but he is just that kind of geek) for the testing.
Yes, I could have and should have tested this on AWS, and it isn’t as though I am a stranger to making Amazon even richer, but I thought since I did my first tests with extracts on one of his servers, I should keep on doing just that.
Thanks again, John, for the use of your Essbase box.
Be seeing you.
12 comments:
Cameron,
I've had some recent experience extracting large volumes of data from a Planning BSO cube on Essbase 11.1.2.0 via the Essbase Java API.
Like you, I found that the best extraction method depends on a number of factors, and no one technique is best for all use cases. Here are some things I found that may be of interest:
Calc script based extracts
Calc script based extracts to a flat file on the Essbase server are the fastest, provided DataExportDynamicCalc is set to OFF. If you need dynamic calcs in your extract, then this method is the slowest. As far as I can tell, this is because Essbase seems to then calculate ALL dynamic calcs in each block, even if you reference no dynamic calc members in your extract script. I suspect this is a bug, and as such it may be specific to 11.1.2.0.
Other drawbacks of the calc-script based approach are that you can't control the order of the columns in the extract file (this is based on outline order of sparse dimensions), and that you can't extract to a client file. You can however workaround this last limitation by extracting to a server file, and then downloading that file to the client - but this means you are then writing the file to disk twice!
Calc script based extracts to a SQL table are slow if you don't have an ODBC driver that supports batch inserts - and 64-bit Essbase does not support batch inserts regardless. On our server, row-by-row inserts made the SQL extract process twice as slow as a file-based calc script extract.
MDX based extracts
MDX queries are the fastest extract method if you need dynamic calc members in your extract, provided you can use NONEMPTYBLOCK, and that you don't try to extract too much data in one query.
Unlike the other extraction methods, MDX queries seem to require memory on the client proportional to the size of the query being run, and so large queries can easily exhaust memory, even when the final data set is not especially large. For example, I needed to allocate my JVM 2GB of memory to get an extract that generated a 100MB file to complete.
To work around this, I broke my query up into multiple smaller queries by partitioning the query into sets of 50 entities. This technique works really well, provided you have a query that can be broken into multiple smaller queries that each on operate on a subset of the cube. You want to ensure that you don't go too far in the other direction, however, and issue thousands of tiny queries, since this then increases your overall query time due to network latency etc.
If you don't have too many dynamic calcs, can use NONEMPTYBLOCK, and can find an optimal query subset mechanism, then MDX based extracts can get close to the speed of calc-script based extracts of stored-only data.
Report script based extracts
Report script based extracts have the best API, as they are the only extract method that can stream data from the server to the client as it is generated. This is also likely why the query times in the Essbase log match the time it takes to actually generate the file on the client.
Although not as fast as the other techniques, the simpler API results in many fewer lines of code, and this ease-of-development may trump the other methods unless speed is an absolute necessity, and you are willing to spend the time testing and tweaking your extract process to find the optimal technique for your needs.
Cheers,
Adam
Cameron,
Of all people, I would expect that you are fully aware of the universal Essbase constant called 'it depends'..
Cheers!!
Joe
Cameron,
Of all people, I would expect you to be aware of the universal Essbase constant - 'it depends' before you would work for 2 days to prove a point.. :)
Cheers
Joe
Simply Joe,
I had to know if Edward had some ultra super secret trick that would make my life easier.
Alas, no such luck. But "It depends" as an answer, no matter how right sort of drives me crazy sometimes. *Why* the "It depends" answer is right is at least something -- I think I have that now.
But yeah, way too much of my time. :)
Regards,
Cameron Lackpour
Adam,
In your testing with the JAPI, did you have an alternate way of writing out the data?
As far as I could tell, the Essbase time was always faster (well, with my very limited test cases it was) than anything else. The performance died when MaxL had to write a 1/2 gigabyte file to disk. I figure if someone has a better way (I have no idea what that better way is, btw) it might be the way to go.
Targeted data extraction is kind of a pain with Essbase. I wish it was a little less gruesome.
Regards,
Cameron Lackpour
Very interesting results, Cameron.
Intrigued by the difference between MDX2 and MDX7. Same output file size, same number of rows, same 'Essbase time' but x2.5 'real time'. Any idea what's going on there?
Cameron,
The Java API for issuing an MDX query returns a data structure that you then query via additional API calls to get at the data.
As such, it is different from the calc script and report script approaches, that can or must take responsibility for writing the data to disk.
The times reported in the Essbase log are therefore not entirely comparable. In the case of a report script or calc script based extract, the time includes the time taken to write the data to a file, whereas in the MDX case, it does not.
Using the Java API to issue an MDX query provides the ultimate level of control over the format in which the data is written to file - but that is because you are responsible for writing the data to file!
Still, this level of control in my mind beats using the MaxL shell, with its hideous output format.
Yet another alternative is to use the the MaxL API to issue your MDX query. This returns a table or recordset like object that is easier to write to a file than the data structure returned from an MDX query, and yet doesn't suffer from the absurd "all columns must be the same width" issue that you get if you use the MaxL shell.
Cheers,
Adam
Tim,
MDX2 was 40 character wide columns, 2 significant digits, no displayed "page" dimension members on row.
MDX7 was 80 character wide columns, 16 significant digits, displayed "page" dimensions members on row.
Basically, MDX7 was writing out a lot more data (there's a space character for each one non-used characters so it was easy to get big, fast, but I needed that to get all of the dimensions into the row header column).
Adam Gardiner has pointed out the tyranny that MaxL imposes via the shell of one column width. If I could have had a large column 1 and then much smaller subsequent columns, things would have been a lot faster.
Ultimately, the issue with MDX/MaxL performance is that MaxL just isn't very good at writing out lots of text.
Contrast that with when the row count is small but the data set to query is large -- MDX spanks report scripts very convincingly and whatever the inefficiencies are of MaxL are not material.
Regards,
Cameron Lackpour
P.S. Before this test, I simply assumed that MDX was always faster overall. It wasn't till I started to try to edit the files did I realize the silly things were still being written to disk. Whoops.
Thanks Cameron, and sorry - I can't read. I actually meant MDX2 and MDX6, which produced almost exactly the same size output file, but in significantly different elapsed time.
Tim,
The only difference bewteen MDX2 and MDX6 is the number of significant digits; 2 for the former and 16 for the latter.
I cannot imagine what makes MaxL more or less efficient writing out spaces versus numbers given the fixed column width but apparently there's quite the difference.
Regards,
Cameron Lackpour
Cameron,
Do you sit up all night doing this stuff?
Hey Cameron,
Sorry if I missed it somewhere, but what version was this on? Judging from the date it was 'probably' 11.1.2.2?
I'm doing a full 'review' of methods of migrating data (everything from Xref->Map Reporting Application->Replicated Partitions->Report Scripts->MDX->DataExports).
One thing that is noteworthy is just how much quicker Dataexport commands are in 11.1.2.3 - a single thread export seems to be averaging around 1gb/min, while parallel exports seem to be getting limited purely by drive write speeds!
Obviously this is BSO only.
Cheers
Pete
Post a Comment