The obligatory disclaimer
I gave a presentation on this very subject at the Hyperion SIG Open Microphone Night. I am not entirely sure that a formal (well, informal, but it was PowerPoint) presentation is 100% a spontaneous thing, but they asked, I double-checked, they agreed, and so it was.
The disclaimer? I am a cheerleader for Dodeca, but not a salesman, not an employee, not a shareholder, etc., etc., etc. Here’s the who-is-this-nut-in-front-of-the-room graphic for those who doubt.
Also, for the record, there were alcoholic drinks there but there was also…chocolate milk and regular milk. 2% and skim. And cookies. Yum. It is somewhat incongruous to admit this at my age, but I really like the taste of milk. I like mixing chocolate and regular milk (so I guess I like watered down chocolate milk) even more. What an awesome idea for snacks.
Back to Dodeca – I like the product, a lot, I don’t do very much with it (if I could sell it, I would, but I can’t very much so I don’t), I do consider Tim Tow both a friend and a mentor, and that’s it. If this post reads like an advertisement, it isn’t. It’s just what the very last bullet point says it is – an interesting way to make processing faster.
Whoops, one more thing. It would be awesome if Planning could pass the contents of the rows and columns to Calculation Manager. Awesome. As you will see if you but continue reading on, gentle reader.
The good and the bad about focused aggregations
In Planning-land, focused aggregations off from forms, at least in the BSO Planning world almost all of us still live in, is the only way to fly. You can read all about it here in detail.
Very, very briefly, the big win is only to calculate the ancestor blocks that are affected by the form. In other words, instead of aggregating an entire dimension, including lots and lots of hierarchies that are not affected by the form input, just aggregate the hierarchies that matter. It’s that easy.
As an example, let’s take a look at the Planning sample application and compare the calculation time of a CALC ALL (not something you are likely to do, but still a valid data point), an AGG of just the two sparse dimensions, and then of course a partially focused aggregation. Remember, this is with Entity in the form row and Segments in the page dimension so Calculation Manager can read Segment via a Run Time Prompt variables but not Entity.
Approach
|
Seconds
|
Percent
|
Calc All
|
5.766
|
3696%
|
Agg of Entity & Segment
|
0.375
|
240%
|
Agg Entity and focused Segment
|
0.156
|
The blocks tell the tale
When we look at how many reads and writes occur, and how many cells are touched via a SET MSG DETAIL statement, it’s easy to see why a focused aggregation is so fast – it simply touches fewer data points. To quote Ludwig Mies van der Rohe, “Less is more”.
Approach
|
Sparse writes and reads
|
Sparse cells addressed
|
CALC ALL
|
22,236 writes
107,570 reads
|
101,820,000
|
Agg of Entity and Segment
|
2,869 writes
10772 reads
|
12,592,000
|
Agg of Entity, focused Segment
|
888 writes
2,960 reads
|
3,897,400
|
Last bit of review
The code looks like ugly but this is how BSO Essbase walks the hierarchies when it does an AGG of sparse dimensions. Weird, it’s true, but it works.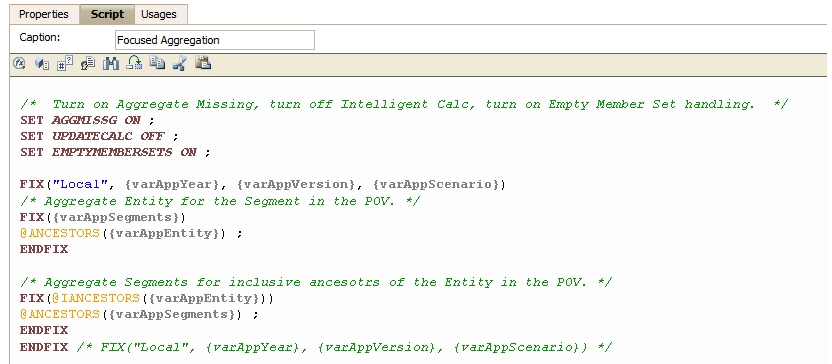
That was the good, here’s the bad
But focused aggregations in Planning have a problem – while they can read the point of view dimensions and drop down or page dimensions, whatever dimensions are on the sheet, and those dimensions’ members are terra incognita to Calculation Manager.
Why care about row and column dimensions? If the dimensions are dense, and if I’ve designed the Planning app, I don’t care – everything is dynamic. But if the dimensions are sparse (and if I’ve designed the Planning app I will have fought this tooth and nail but sometimes that’s just the way people interact with data), I do care because that means any aggregations off of the form will require a full AGG. Not so focused, is it?
What oh what to do? In Planning – there is not a blessed thing. However, what if the application in question was Dodeca?
What Dodeca can do
The problem with the focused aggregation approach in Planning is as I stated – I don’t know what the sparse dimensions on the sheet are, nor do I know the scope of the member selections.
If I did know that, why then I could write focused aggregations up to the top of the dimension and down to any subtotals. In other words, a super focused aggregation with hopefully super fast results. How oh how do we do this? It’s actually quite easy.
Dynamic Rowset to the rescue
All I need to do is modify the approach I wrote about back in December of 2012 on how to do a dynamic rowset report in Dodeca and change the database from Sample.Basic to the Planning sample application. And once I do that, I then need to take advantage of the selected Entity and insert it into my Dodeca-specific calc.
To review: a Dyanmic Rowset report takes a user selecting in a dimension, figures out what the descendants (or children or siblings or whatever) are, and then sticks all of them on a sheet via an Essbase report scritpt, MDX query, or delimted list. Dodeca does all of this through something called a Workbook Script – sort of Dodeca’s enlightened approach to coding.
Set up a few ranges on the sheet to indicate where the retrieve range is and where to insert rows, and then “code” by modifying the below Workbook Script that fires when the workbook itself opens up, but before it retrieves.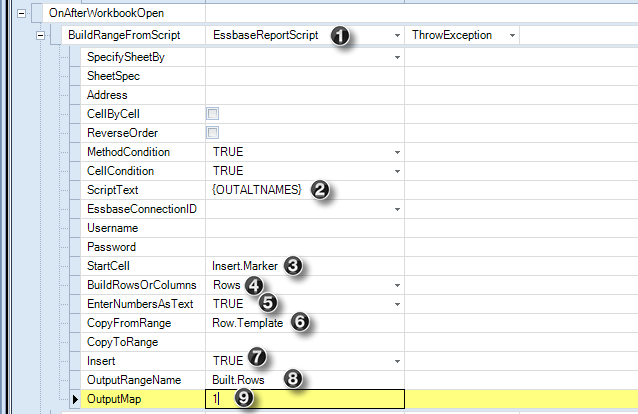
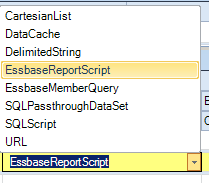
- BuildRangeFromScript – I chose the the EssbaseReportScript type; there are many ways of doing this including MDX (cannot be seen because this is an older release):
- ScriptText – Code to actually build the rows. Tokenized to push the value of the select from the dimension treeview.
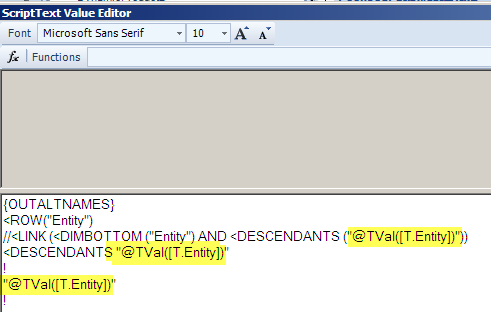
- StartCell – Range name of the repeated rows that are tied to the output from ScriptText. This is the green range.
- Rows – This report has dynamic rows; it could just as easily be columns.
- EnterNumbersAsText – Just in case member names such as 100 are used, treat them as text.
- CopyFromRange – The name of the range to be repeated. This is the blue range.
- Insert – Set to TRUE as I want the output of ScriptText to be reflected in the sheet.
- OutputRangeName – The name of the rows that are built during the insert process.
- OutputMap – The column that receives the output of ScriptText.
When all of that is built, and the rows are placed onto the sheet, Dodeca does its retrieve. Magical, isn’t it?
A short note about tokens
Do you like Planning’s Run Time Prompt variables because of their utility in Calculation Manager? If so, you will really like Dodeca’s tokens because they are even more powerful. Tokens work in report scripts, calc scripts (just like RTP variables in Calculation Manager), and they work in retrieves as well.
You saw above how a token with a Workbook Script function to force the valuation of the token worked in getting the content’s of the rows
Within a report (aka an Excel sheet) before:
And after in Dodeca: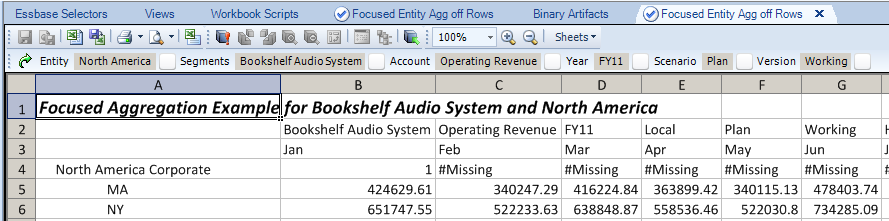
And in the calc script itself: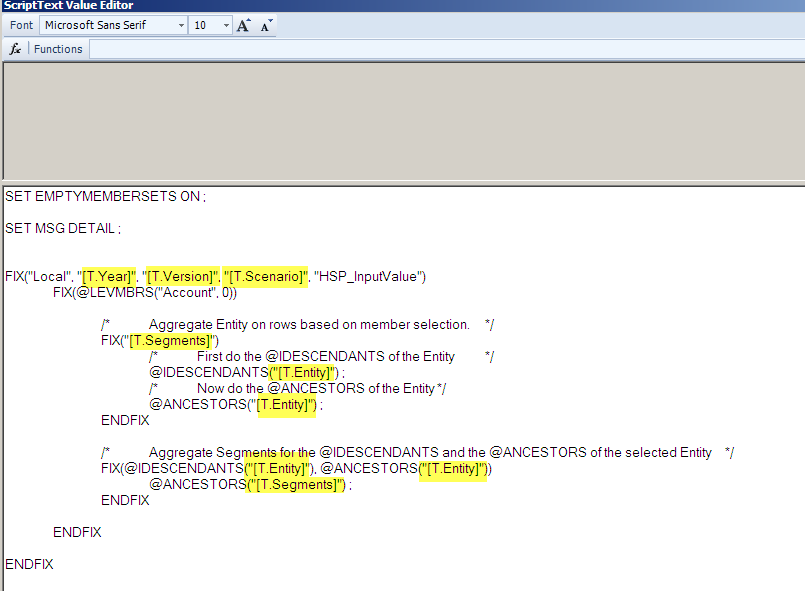
Did you catch the clever cannot-be-done-anywhere-else bit?
It’s as easy as 1, 2, 3.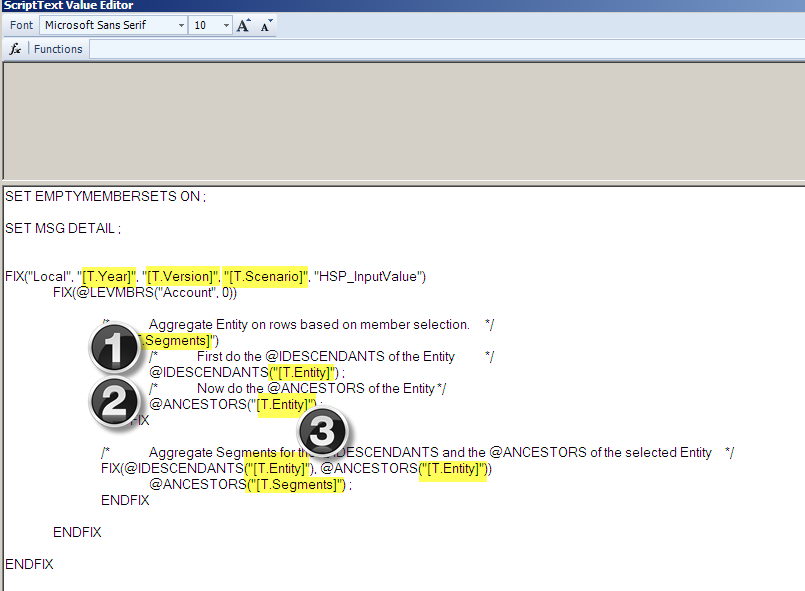
1 – After fixing on whatever the Segments dimension member is, calculate the inclusive descendants of the Entiy dimension that drives the rows.
2 – Within that same FIX, calculate the ancestors of the Entity dimension.
3 – Then FIX on the inclusive descendants and the ancestors of the Entity dimension that drives the rows and aggregate the ancestors of the Segments dimension.
We’re done. It was easy, and awesome.
What’s the payoff?
Time
The payoff is speed, a lot of it. Let’s review the speed again, but now with the above row-based focused aggregation. The difference is dramatic. The Dodeca focused aggregation is 93 times as fast as a Calc All, 6 times as fast a dimension aggregation, and 2.5 times as fast as a partial focused aggregation. Would you like to speed up your budgeting aggregations by a factor of 6? Or 2.5? You bet you would. And you can, quite easily.
Approach
|
Seconds
|
Percent
|
Calc All
|
5.766
|
9300%
|
Agg of Entity & Segment
|
0.375
|
605%
|
Agg Entity and focused Segment
|
0.156
|
252%
|
Dodeca agg of focused Entity and Segment
|
0.062
|
Blocks
We can look at time or we can look at the blocks. If time = money, then time also = blocks. The fewer are most definitely the better. The percentage improvements in sparse cells touched by the aggregations mirror the time pretty closely.
Approach
|
Sparse writes and reads
|
Sparse cells addressed
|
Percent
|
CALC ALL
|
22,236 writes
107,570 reads
|
101,820,000
|
7733%
|
Agg of Entity and Segment
|
2,869 writes
10772 reads
|
12,592,000
|
956%
|
Agg of Entity, focused Segment
|
888 writes
2,960 reads
|
3,897,400
|
296%
|
Dodeca focused Entity and Segments
|
300 writes
1,000 reads
|
1,316,700
|
Takeaways are not necessarily fish ‘n chips
1 – Focused aggregations are good because they can make your aggregations quick.
2 – Planning can’t give you the rowset for a sparse aggregation although it’s way better than nothing.
3 – Dodeca can give you the rowset for a sparse aggregation through a combination of Workbook Scripts and Tokens.
Try it, you’ll like it. :)
2 comments:
Hello cameron, first of, thanku for sharing the concept of focused agg. Second, I have been burning fuel in my brain to work this approach since last 2 days, hoping you can help me out.
In your example, there is only entity and segment dimension. Whereas, my form has entity (selected lvl 0 values) From shared hierarchy in the page drop down. Rest of the pov is 4 other dimensions, region, product, risk and vendor...All selected as defaultsmm.no product, No region..and so on.. The rows are accnts as dense dimension and the upper level members are dynamic and columns is time periods which is a shared hierarchy again. Now, how do I use your script instead of
Fix (scenario, year, version)
Agg (entity, product, vendor, risk);
Endfix
I am worried the above will create performance issue if I save this to the form.
I tried to declare entity as a variable and wrote:
Fix (scenario, version, year)
@allancestors ({entity})
End fix
It doesn't even deploy as a green check. The rule doesn't do anything. I declared entity as members in variable with default value. The user can select multiple departments in a form and enter data at a given time.
Hi Cameron! Big admirer of you and your work!!
I'm Marcos, and work together with Ricardo and Rodrigo (the Brazilian guys who make crazy things with ODI reusing EVERYTHING and maintain many apps with almost a single component there, shown in Kscope 13, 14 and 15)
Here's my 2 cents and sorry if i miss by too far:
Theoretical scenario: Hyperion Planning and Calc Mgr (no Dodeca yet)
Planning only allows loading into Lev0 entities if version is bottom-up (as usually is)
So if users choose one Lev_N entity from the POV or vEntity var, is it fair to say the associated Rule is meant to process ONLY @relative(vEntity,0) members and then "focus" aggregate?
If so, wouldn't be better to "process" the vEntity, populating a MemberS variable vEntitieS = @relative(vEntity,0) and (here's the trick) writing the Rule knowing that it always receives a list of level 0 entities?
This way you can simplify the aggregation part by just calling @ancestors(vEntities) without having to call the @descendants part
The advantage I see here (a need from the company too, since ages ago) is that you can REUSE this Rule to let users load data in many level 0 entities via SmartView.Essbase or so, and then call THE SAME Rule just once, passing the list of Lev_0 entities
In my case (challenge? asking for help?) I can't simply use a DTP that passes @relative(vEntity, 0) to the rule, since (calc language limitation) @ancestors(@list(@relative(vEntity,0))) works in the FIX declaration but not outside it (for later aggregation). It HAS to be @ancestors(@list(mbr1, mbr2, ...)) so we must POPULATE the vEntities var with the members list (and not the function) in a script BEFORE calling the actual rule ... is that possible?
Thanks, and sorry if the alternative/challenge is too specific
Post a Comment