Introduction
At the end of July Tyler Feddersen very generously wrote part one of this two part series on data validation in Planning; you now are reading the concluding entry. I’ll let Tyler do the explaining below but I want to make sure you, Gentle Reader, understand that other than this introduction and a super short concluding paragraph that everything is 100% Tyler’s. I don’t have many guest bloggers (if you are interested send me a comment via this blog or a LinkedIn message) but I am always beyond happy to use my blog as a platform for sharing information.
Thanks must also go out to Performance Architects – not many companies (in my experience, “not many” should read “just about none”) would allow one of their employees to write for something other than their blog. PA are to be commended for their spirit of information sharing. Chuck Persky, whom I know from the long ago days of ISA (and thus my connection to PA), will be presenting at Oracle Open World – if you are going to that event I encourage you to attend his session Oracle Planning and Budgeting Cloud Service: Oracle Hyperion Planning in the Cloud [UGF9091] on Sunday, 28 September. I’m not presenting on that Sunday (or at all at OOW, for that matter – sanity occasionally comes my way), but I am the guy who solicited the ODTUG EPM user group sessions. And lest unworthy thoughts enter your mind, I reached out to Chuck long before this blog post was written – there is no quid pro quo.
With that, enjoy.
Tyler Feddersen, Performance Architects
Let’s take it a step further
If you are reading this and have not read Part 1, I would definitely recommend stopping now and doing so. The rest of this blog will be taking the results of Part 1 and taking it a step further in creating a pretty good overall validation solution.
The validation process discussed in Part 1 was a simple way to be able to identify errors that would cause data integrity issues. However, it does not prevent them. This is the part of the process that Part 2 will attempt to accomplish.
A Look Ahead
Each individual step with this solution is fairly simple and direct. However, the process that combines them all starts to get a little confusing. Let’s take a glance at the general process flow that an end user would go through when working with this technique.
- The user completes all necessary data entries
- Following data entry, the user would change a lock status to “Locked”
- Done through a separate entry form
- A business rule checks for any errors prior to allowing the lock
- Causes a flag to show as “Locked”, which also prevents additional business rule execution
- If Process Management is used, the user would approve the entity, which would validate against the data form used in Step #2
- If approvals process finds that the entity has not gone through the initial locking process, an error will be displayed
- By successfully approving, the user is no longer the owner of the entity
- Following a successful approval, the user is no longer able to perform any data entry, which means that the initial lock in Step #2 cannot be reverted
- At this point, the user would need to have the entity sent back through Process Management in order to perform any further data modifications
The end result of the process allows for analysts and administrators to switch their focus to more business-related issues rather than focusing on locking down the system and having to check for all of the typical data entry errors. Administrators generally have to pick a universal end date to lock down the system in order to be assured that users are not making additional changes. With the process mentioned above, budgets and forecasts can be potentially analyzed as they are completed since a user’s ability to make any modifications is removed as soon as everything is approved.
The important part to remember is that this process is done completely using out-of-the-box functionality. If there is anything through the steps that you feel could be simplified….it probably could. But this will at least get us started.
Step 1: Dimensionality
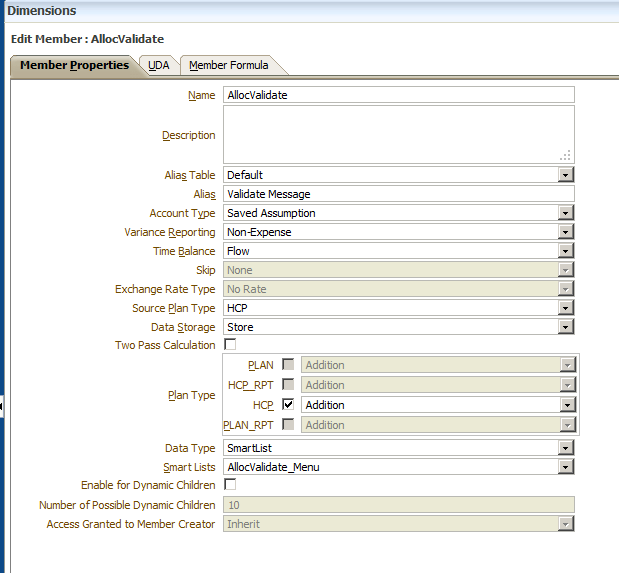
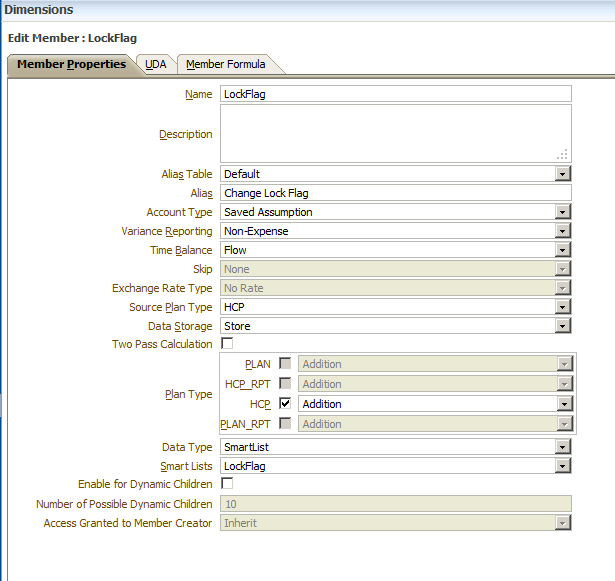
If you recall from Part 1, I created two validation members: AllocValidate and Validate. AllocValidate was created in the dense Accounts dimension while the Validate member was created within a sparse dimension, to give us block suppression capabilities. For this portion of the validation process, I created an additional Accounts member, LockFlag. This new member will be used in coordination with the previously created member, AllocValidate, to create a locking “flag” that all business rules can use to decide whether the rule should continue to process or not.
Additionally, I added a “NO_XXXX” for each dimension. The flag only needs to be stored at the Entity level, so each dimension outside of Accounts, Period, Scenario, Version, Year (although, I use No Year), and the dimension containing “Validate” will need the “NO_XXXX” member.
Step 2: SmartLists
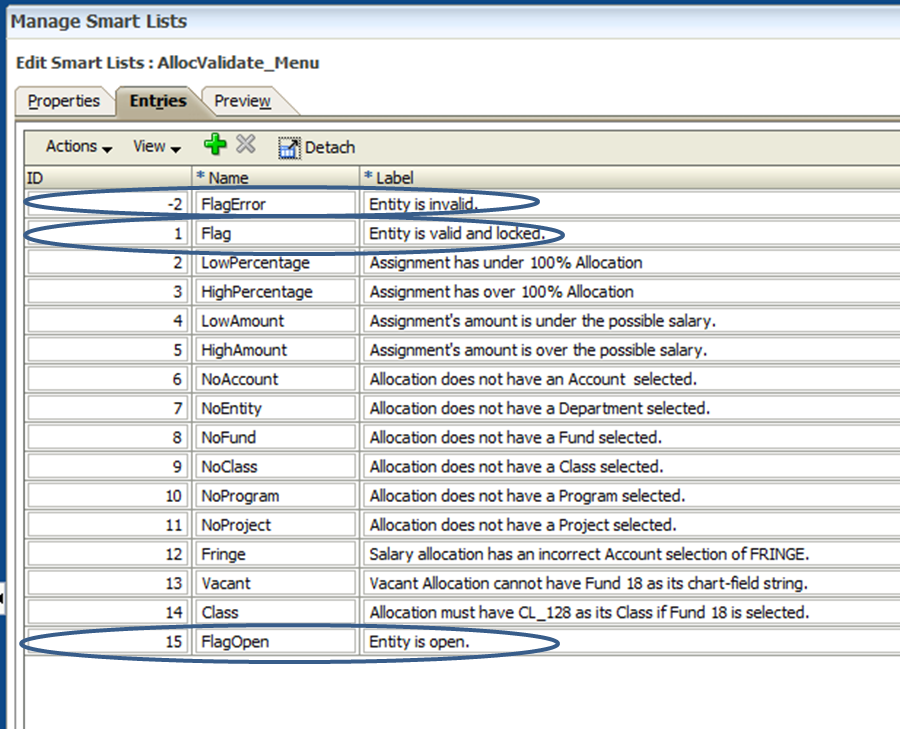
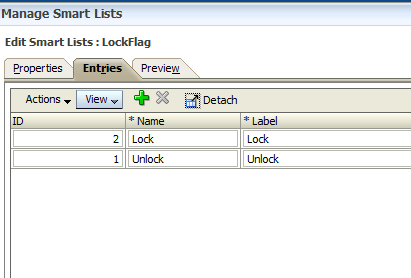
Building off the SmartList from Part 1, I added a few new entries. These entries will be used to display the status of an entity in the approval process, including: locked, open, and invalid. Additionally, I created a new SmartList to accompany the “LockFlag” member. This SmartList will be used by the users to lock and unlock their entity.
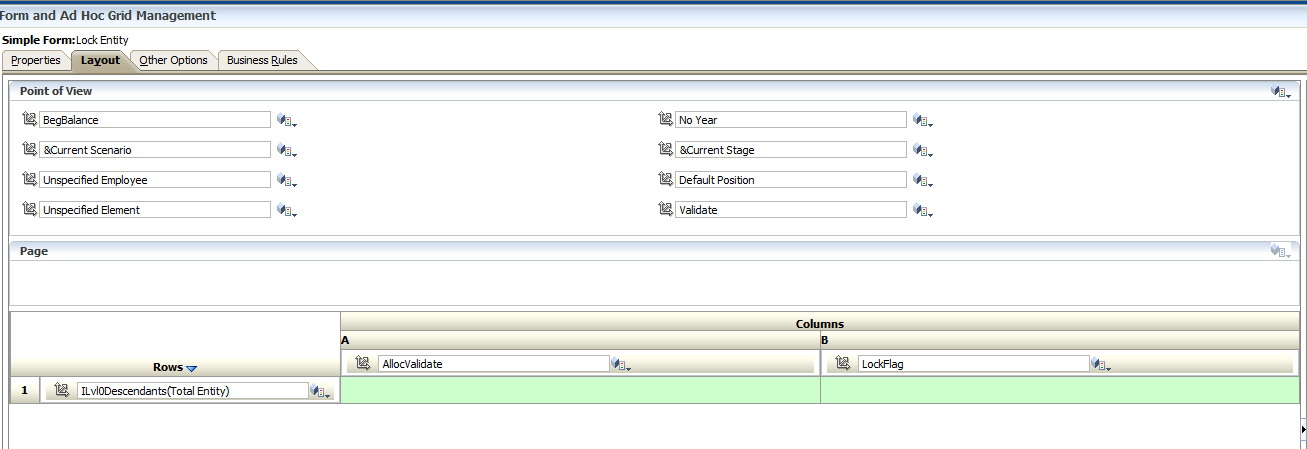
Step 3: Create the Data Form
Create a data form with following parameters:
Rows: Entity
Columns: AllocValidate and LockFlag
POV: All other members where the flag will be stored (including Validate)
Additional Specifications:
- Make the column for AllocValidate Read-Only. This column will be modified based on the user selection for LockFlag in coordination with a business rule that will run on save.
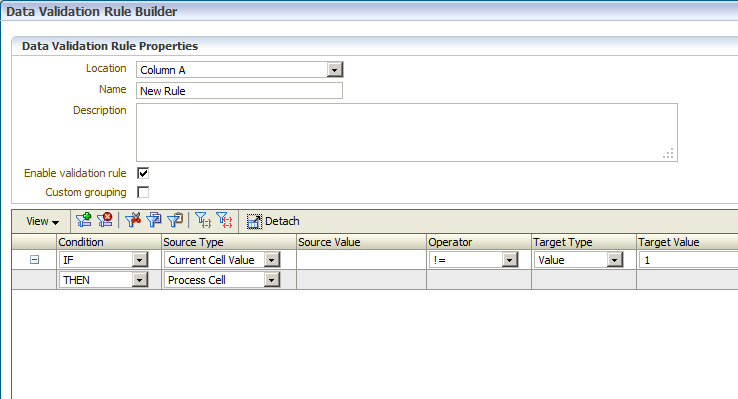
- Add a Validation Rule for the AllocValidate column to show as invalid if the column does not appear as being locked.
Step 4: Business Rules
First, create a rule to run on save that will check for the “LockFlag” selection and update the “AllocValidate” status accordingly. The script should initially check if an entity has any error messages. If not, then it will lock or unlock based on the LockFlag selection. Note that this rule actually runs for all entities each time the save occurs. However, there is very little to no potential conflict issue between users, as the rule runs very quickly. However, this rule can also be run as a Menu option to select a single entity at a time if desired. An example script is shown below.
The rule checks if any validation errors already exist. If so, it changes the AllocValidate flag to appear as invalid.

If the rule detects an invalid entry, the rest of the rule is not processed. If there was no error found, the rest of the rule will lock or unlock based on the LockFlag selection.

Next, update each business rule to take the “AllocValidate” flag into consideration. If the flag’s current status is “Locked”, then we no longer want to run the business rule if it will change the current data set. An example is shown below, using the @RETURN function as well.

Lastly, I’ve udated the rule that was created in Part 1 to include an automated re-assignment of the AllocValidate lock status to be invalid, if an error occurs. This is to prevent an issue where the user locks the entity but then submits invalid data, as data entries cannot be prevented through the use of business rules. The example below would assign an error to a specific assignment in addition to assigning the “Invalid” flag for the whole entity.

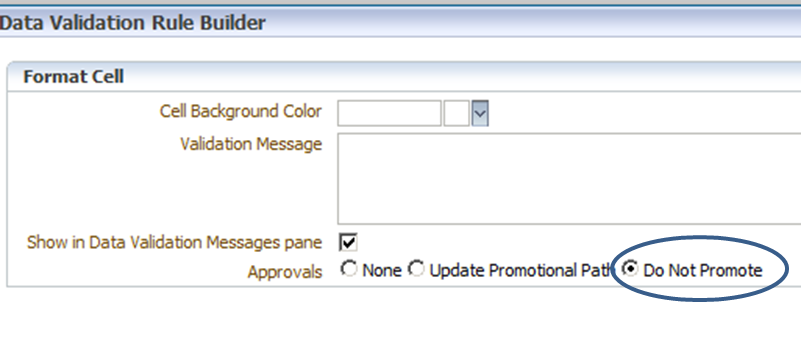
Step 5: Process Management
Process Management is a fairly complex subject within Hyperion Planning, so I will not be going into a lot of detail on the specifics of setting everything up as that could be its own blog…or two. The assumption here is that the decision has been made to use Process Management, which allows it to incorporate this validation process. The important part is to make sure to select the checkbox “Do Not Promote” within the options for the Validation Rule set up in Step 3. This will cause approvals to fail if it detects an error within the data form.
Step 6: Example
If you’re confused at this point, it’s quite understandable. I am as well. Nonetheless, let’s put everything together and actually go through a sample process that a user might go through.
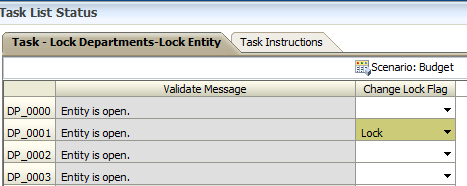
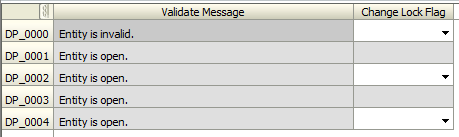
- The user has invalid data and is trying to lock department (entity) DP_0000. However, the rule has found a validation error.
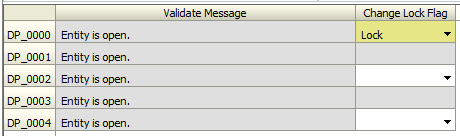
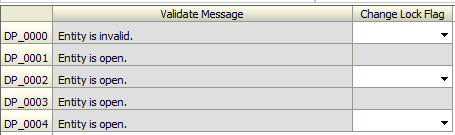
- The user can navigate to a form with the list of errors affecting all of their entities. The example below was the form that was created in Part 1.
- The error is displayed on the form, and the user fixes the error. Note: My error flags were thrown off during the preparation for this demo, and the error doesn’t EXACTLY reflect the real error. We’ll pretend.


- After fixing the error, the user navigates back to the locking form and tries to lock again. The lock is successful this time.
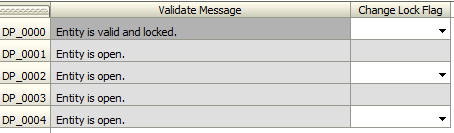
- The user tries to run a rule to add a new position to the department that has been locked. Since this rule would change the data set that has been validated, an error is returned.
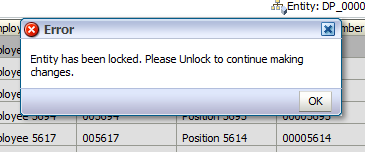
- The user goes back into the data set, entering a change to the data set that will cause an error to occur. The flag is automatically reset to be invalid.
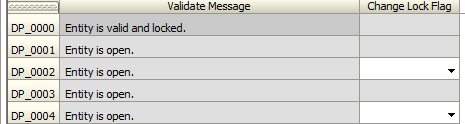
- As an example for Process Management, we’ll pretend the user has approved the department successfully. In doing so, the depatment can no longer be unlocked unless the department is sent back, creating a completely locked down department.

Conclusion
By now, you probably get the gist of what is trying to be accomplished here. However, it all can get a litlte complex with how all of these pieces interact with each other. As mentioned earlier, all of these steps are just an example of how all of these pieces can work together to create a customized flow within any Planning application. They can be refined, simplified, or even expanded as needed. The best part about all of this is that it’s simply a new take on existing functionality, allowing developers and users to remain within the Planning technology. With the Hyperion functionality, we’re always attempting to achieve higher efficiency, and there is nothing more efficient than removing some redundant tasks from the administrator’s plate. Thanks to all for reading and a special thanks to Cameron as well for allowing me to hijack his blog for a few entries. Let me know if you have any questions or comments!
Cameron’s conclusion
So there you have it – a way to prevent planners from inputting incorrect data values. It’s sort of the budget data quality Holy Grail for Planning administrators and consultants alike. And oh yeah, business owners too. This is awesome stuff and again my thanks to Tyler Feddersen for writing this and Performance Architects for allowing Tyler to write outside the walls of his company. PA understands that sharing information is how we all grow and learn. Thanks for sharing, guys.
Be seeing you.



























