Let’s talk about allocations of the most simple kind
Before I go any further, I must give credit to Tim German aka Cube Coder aka @CubeCoderDotCom. He and I came up with this approach as part of our Kscope15 presentation ASO, BSO, and Hybrid Calculations: What’s Fastest, How Hard Is It, and Which One Should You Use?. Never fear, this isn’t merely a rehash of that presentation as I go into quite a bit more detail in this post. Also, this is the Fast, Cheap, & Out of Control straw man proposal. The next post will be (hopefully) quite a bit more sane.
To set the stage, this allocation post will:
- Use a Hybridized version of Sample.Basic
- Allocate the indirect Budget cost Distribution from a pool amount
- Use a driver based on Actual Sales level 0 Product and Market as a percentage of Actual Sales Total Product and Total Market
I (and the world+dog of Essbase developers) have written allocations like this since the Year Dot. I purposely chose this example because it is so basic and yet pervasive. Never underestimate how easy Essbase makes this sort of logic. I think sometimes we lose track of the still-revolutionary functionality of Essbase. But I digress for the eleventy billionth time in the life of this blog.
Danger, danger, danger
The title of this post contains “Wild and Crazy” and what I will show you will make your eyes pop out albeit not in a SNL 1970s Golden Age kind of way. Nope, this one made my brain hurt when I wrote it. I suppose that’s all a long way of saying that what I going to illustrate you works but you almost certainly should never, ever, ever use this technique. Think of it as a laboratory experiment that shows an interesting approach but is impractical in the real world. I have been burnt by too many other consultants’ “genius” to not want to touch this approach with a 40 foot barge pole and I don’t want you to go this way either.
I write this post to illustrate how this could be done and only that. And then to provide an approach to contrast in the next not-completely-insane-approach blog post.
You Have Been Warned.
But first what is the logic?
The goal is to allocate an indirect cost, in this case the Budget cost of distribution, to all level 0 Products and Markets. Yes, this is Sample.Basic yet again, and why not?
Expenses are entered at a level 0 in a pool member
The Budget data points to be allocated are at level 0 in each dimension. Note that No Market, No Product, and Pool are non-consolidating members specifically used to contain the data and not aggregate.
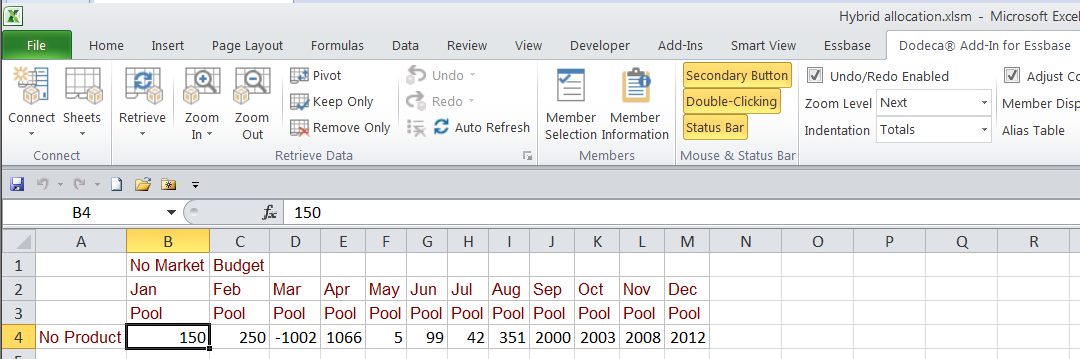
Calculate percentages
The allocation percentages are an interim step, normally never viewed.
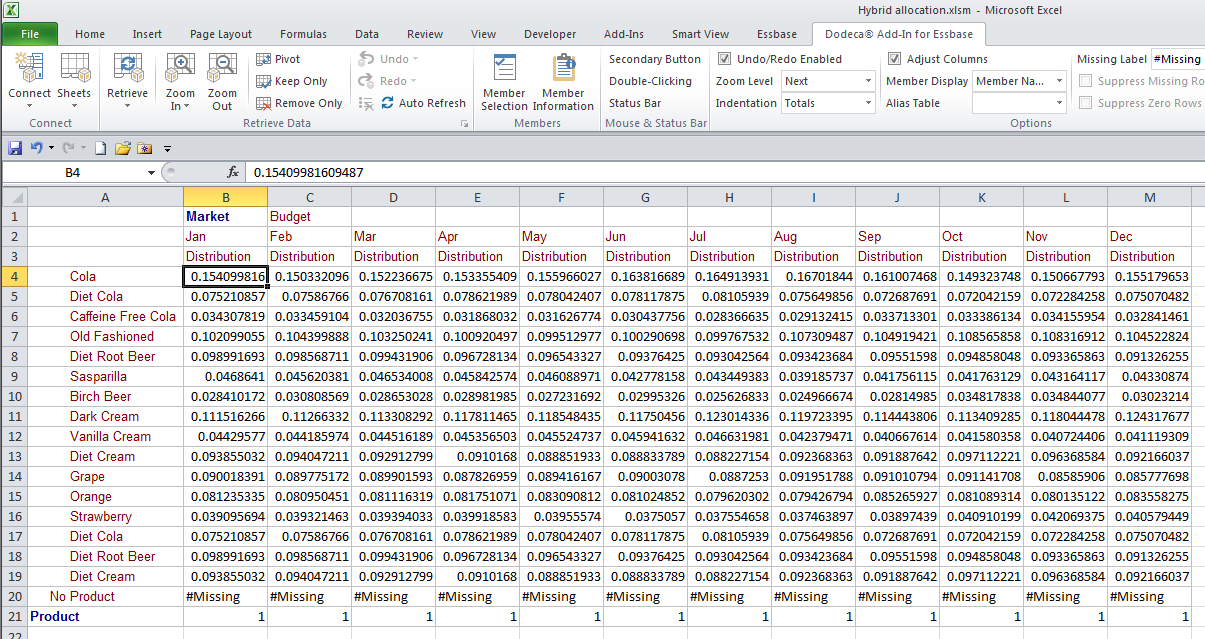
The allocated and aggregated results
Ta-da, Budget Distribution is now fully allocated.
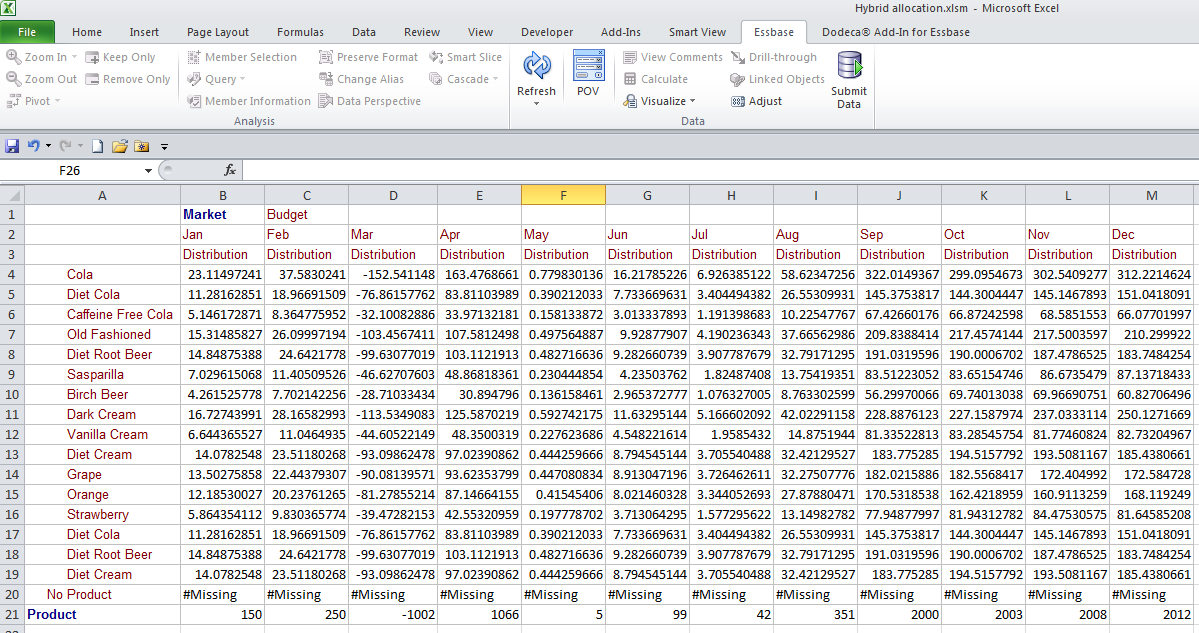
With the logic out of the way, let’s delve into how this actually works across the various engines.
The BSO way
Outline
Surely you are familiar with this. Certainly the readers of this blog are.
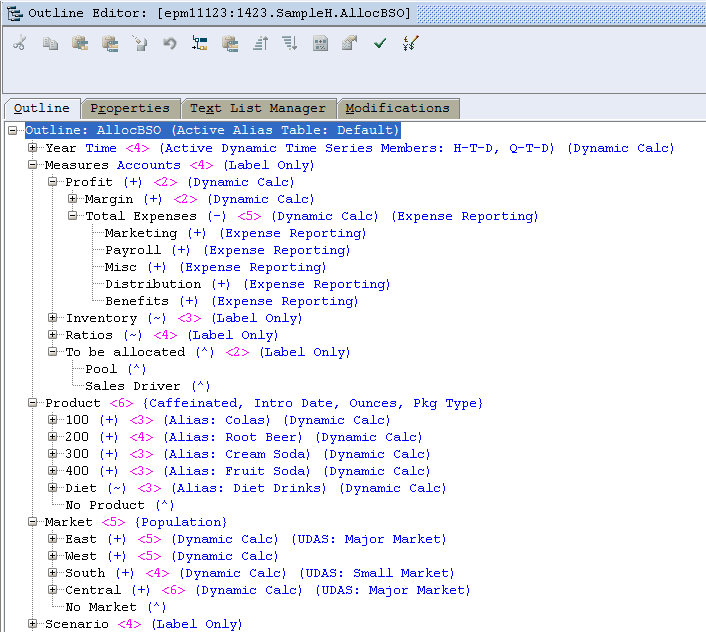
Assuming an already aggregated Sample.Basic, the code is as below.
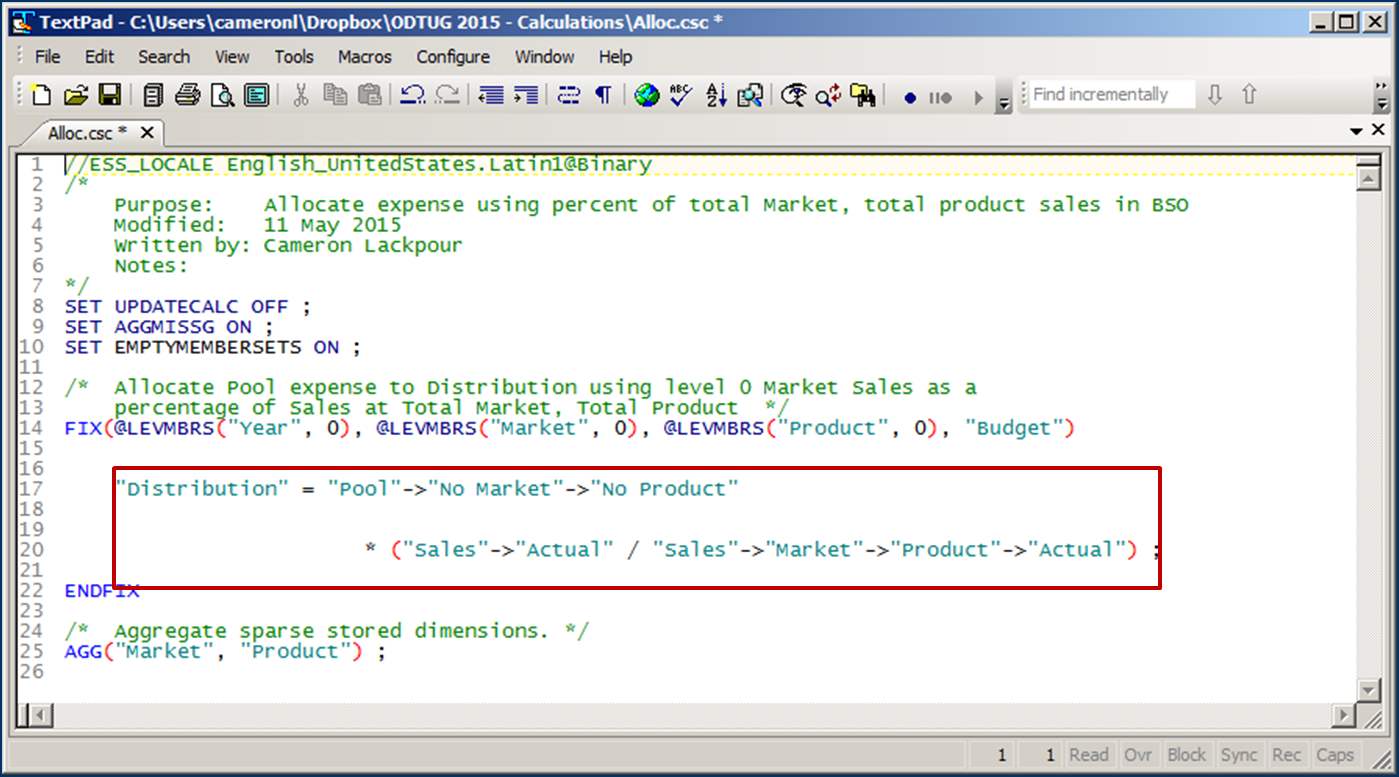
Broadly, the code is as follows:
- FIX at level 0 Product and Market as well as period.
- use the percentage calculated from level 0 Product and Market sales divided by Actual Total Market and Total Sales.
- Aggregate the Market and Product dimensions.
As I wrote, easy peasy lemon squeezy.
The problem with Hybrid
Hybrid is great, Hybrid is fast, Hybrid is the best of BSO and ASO, Hybrid is the bee’s knees, Hybrid is the berries and yet at the same time, Hybrid sucks. What? Mr-OMG-I-love-Hybrid has a problem with the tool? Actually, yes I do. As Maxwell Smart would say, “Missed it by that much”.
What’s the problem? The whole raison d’etre behind Hybrid is that it uses an ASO engine wherever dynamic sparse member calculations exist; those are then dynamically aggregate via ASO. This gets around the the problem BSO has with scaling in the form of calculation time and disk space, the gruesome-to-some MDX, and the opaqueness of ASO calculations scripts.
Disk size isn’t much of a big deal today in the face of multi-terabyte hard drives (if this blog is around in five years, how we’ll all laugh at that as “big”) but a large collection of .PAG files is indicative of a long aggregation time; time is a constant as measured by us on Earth. BSO’s genius is its retrieval speed (none of the engines beat it save for attributes) but its Achilles Heel is its inability to scale to larger databases.
If the ASO component of Hybrid is the solution to scaling, what’s the problem? Those upper level Hybrid-enabled queries only work in a retrieval tool (Smart View, FR, etc.) and in MDX; FR only takes advantage of Hybrid if MDX is the retrieval language. Where they don’t work is in calc scripts as of 11.1.2.4. IOW, if you were to write a calc script that requires an upper level cross-dimensional reference that is retrieved via the Hybrid engine, i.e., just like this allocation process requires, the calc script will validate, and will work, but when that calc script refers to that upper level member, Hybrid reverts to true BSO sparse dynamic calculations. This can be A Very Slow Thing (almost as long as that lovely run-on sentence above) and most certainly Something You Don’t Want.
As of 11.1.2.4.00x, there are only two ways to get ASO-drive Hybrid upper level data out of Essbase:
- Run a query in Smart View/FR (again using MDX only)/etc.
- Use MDX to get the data out – remember, neither DATAEXPORT or Essbase report scripts will export Hybrid upper level data.
I never promised you a rose garden when it comes to a clean approach. This is a Stupid Hack after all.
What to do, what to do, what to do?
The answer is decidedly blue. (If you’re not a fan of the American Songbook, and you clicked on the link to hear that, and you’re still not a fan of the American Songbook, there is really no hope for you. And if you aren’t a fan of the Velvet Fog and King Cole, well, I’m so flabbergasted I can’t even rant about it.)
It’s all in the wrist
The Stupid Trick is to load upper level data into level 0. By that I mean: retrieve data from an upper level intersection and then load that data into a level 0 bucket. Then when the allocation process occurs, the calculations are all level 0 BSO. The beauty of this approach is that no aggregation (other than what Hybrid performs via its ASO engine) is required so in a budgeting scenario, the turnaround between input and allocation and retrieval of the spread data should be very quick.
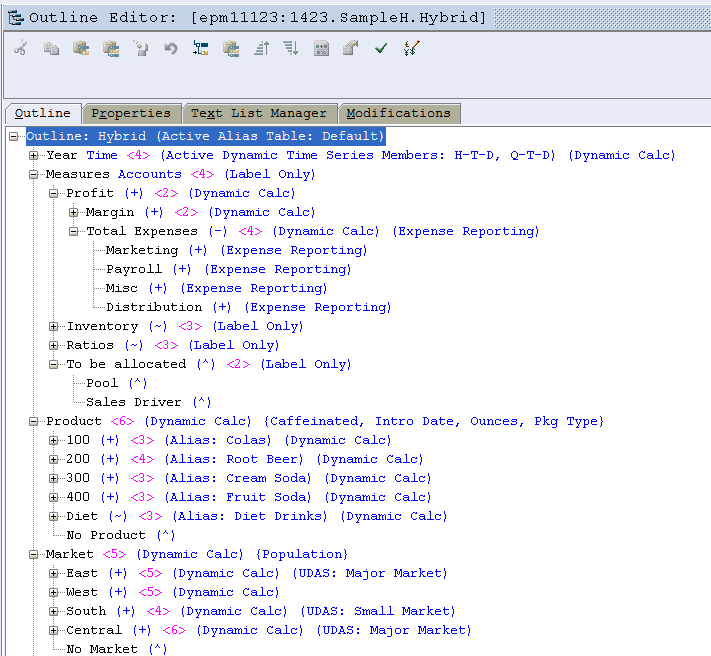
Peas in a pod
The only difference in the Hybrid world is the upper level sparse members. Where they were stored in the BSO Sample.Basic in SampleH.Basic those members are set to dynamic calc.
Getting it out with a MDX crowbar
MDX is many things – powerful, flexible, a language with a fetish for parenthesis, square brackets, and curly braces – but one thing it is not is a good data extractor. It works, but you’ll not be well pleased with the result.
Before I go into that particular rant – no worries, it’s coming – let’s take a look at this query.
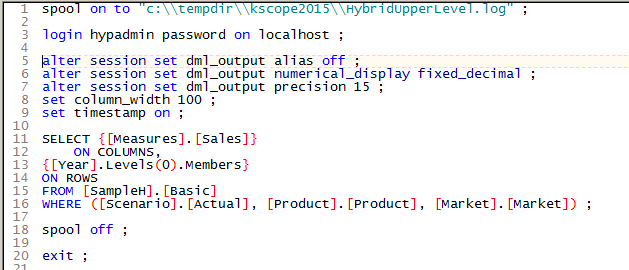
Not that bad
I am, to be charitable, not very good at MDX but even yr. obt. svt. was able to figure this one out.
After setting display properties (and giving you my VM’s username and password), the query:
- Selects Sales
- Puts periods in the rows
- Restricts the retrieval to Actual, total Products, and total Market.
Quite bad, actually
If I had a $, £, ¢, R, etc. for every time I heard someone complain about MDX output over on Network54 I might not be a very rich man, but I’d at least be able to afford a better brand of Scotch.
Look at this. Lord love a duck, this is gruesome. And the gruesomeness is about to get much worse.
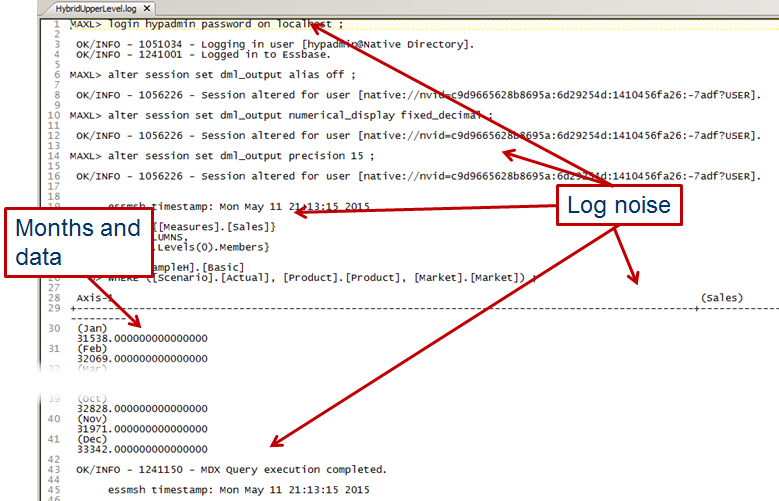
I don’t want header information, or the query repeated in the spool file, or column headers, or query success messages. This isn’t too much of a good thing, it’s just too much and most if that I don’t want.
I want doesn’t get
If Essbase is going to read the file it must be cleaned up and made fit for purpose via a parse of the file. I am going to use a commonly used language in the EPM world – VBA in the form of VBScript to do so but as you will see it’s not an ideal tool. Read it, marvel and its awfulness, and think about how you would do it in Perl or Groovy or Jython or just about anything else.
VBA est omnis divisa in partes tres
Unfortunately, I am not as pithy as Julius Caesar but I do my bit. Also, I wish I taken Latin classes, Classical (not Demotic as that might actually be practical) Greek, and more than just a few courses in philosophy. At least I get to be a singularly focused autodidact in practically every aspect of my life. And have a job.
A fish rots from the head down
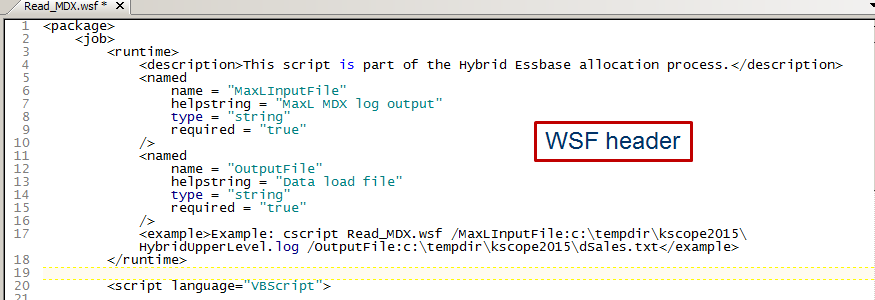
A Windows script (*.wsf) file is a text document containing Extensible Markup Language (XML) code. It incorporates several features that offer you increased scripting flexibility. Because Windows script files are not engine-specific, they can contain script from any Windows Script compatible scripting engine. They act as a container.
In the case of this script the header defines two required parameters: the name of the MaxL file to be parsed and the name of the output text file.
‘Cos I can be a bit of stickler when it comes to code, I’ve included the optional <example> node.
Lastly, the script language, VBScript, is defined.
The Mystery Meat
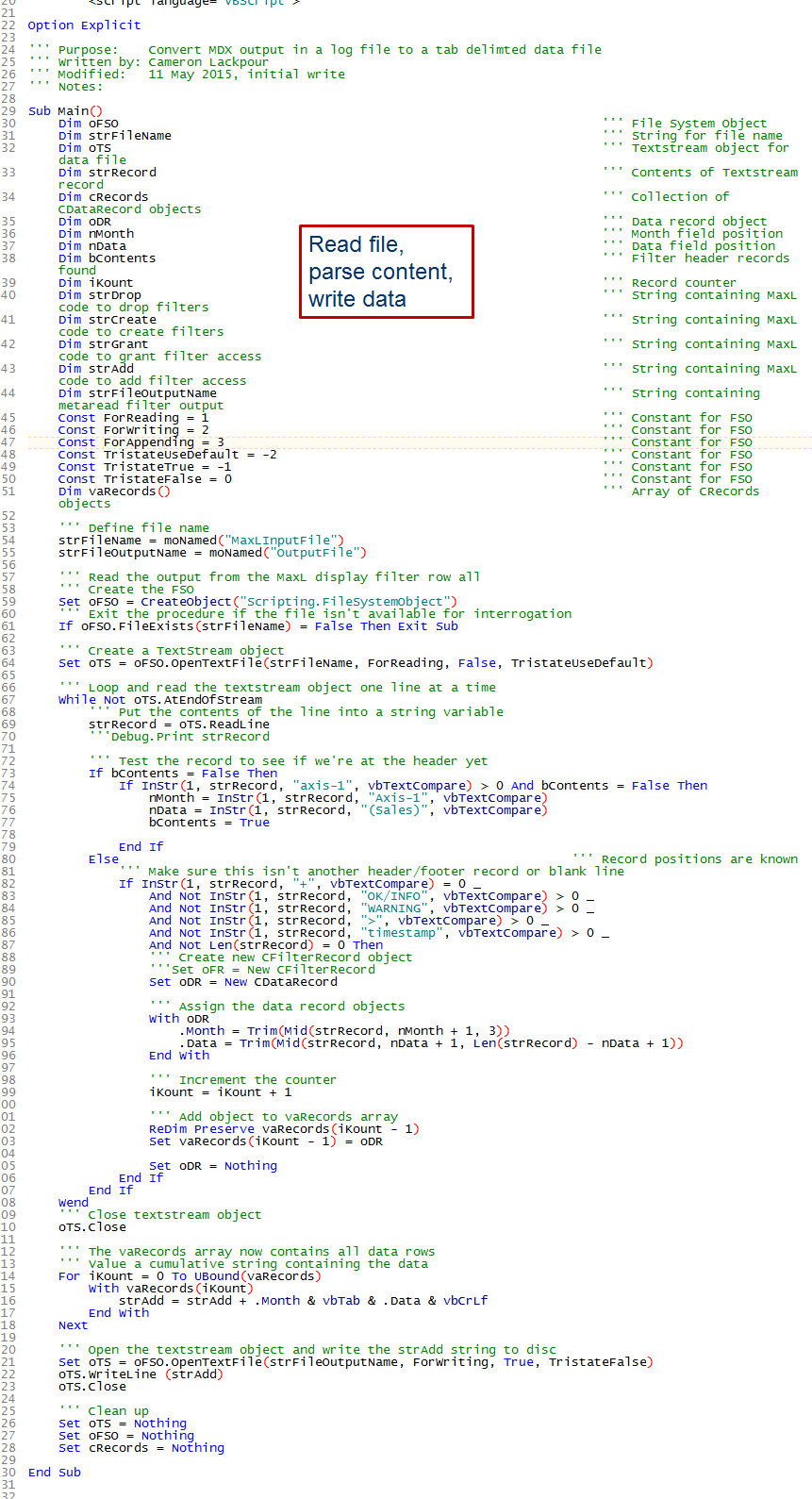
The MaxL MDX query output is beat-it-with-a-stick ugly. So is this code albeit better formatted. At least I destroy all of my instantiated objects at the end of the code.
Feet do your duty
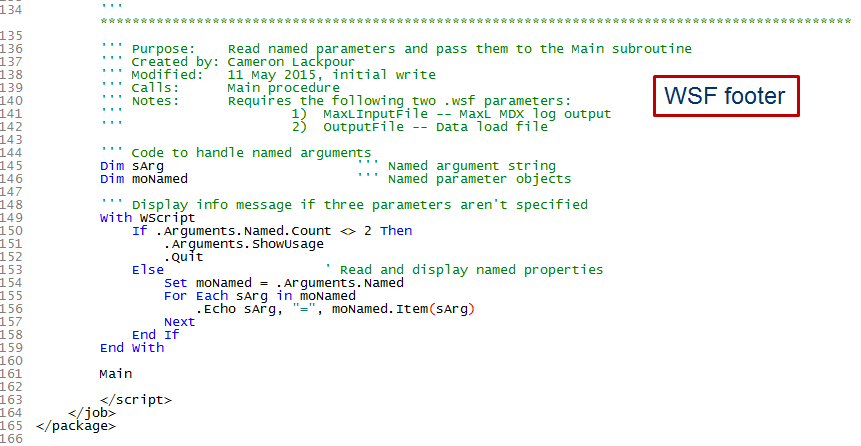
Interestingly (to some at least), the actual execution of the code is controlled at the end of the script. Why? Why not at the top? Damfino.
In any case, the footer reads the arguments, ensures that they are valued, and then calls the Main procedure.
Call it names
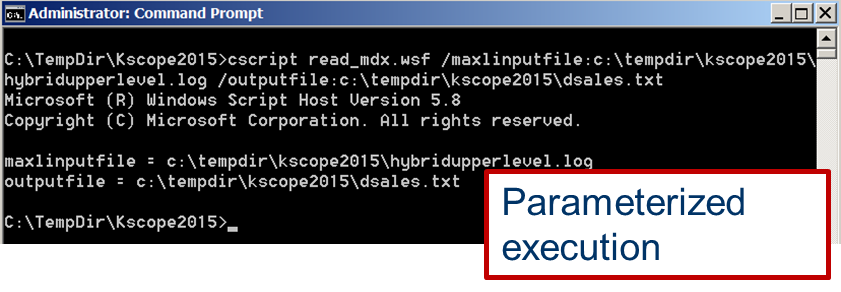
Running it isn’t so awful and once written, runs a treat. I’ve even named the parameters and echo their values. Ah, that pat on the back feels so good.
The output we’ve all been waiting for
An awful lot of pain for not much return. At least it’s readable, although it still requires a tweak or two for Essbase.
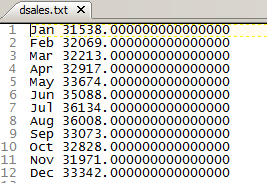
But at least the stupid thing is readable by Essbase. Almost.
Glenn, this is the moment you have been waiting for
Does success taste best when served cold? Yes, MMIC, I am going to use an Essbase Load Rule and I am going to use it to do ETL. Oh the shame, oh the ignominy, oh the hack, oh the hypocrisy.
Yep, there it is – I’m hardcoding (gasp) the dimensions that aren’t defined in the from-the-Hell-of-MDX-query file to load those upper level members into level 0 buckets.
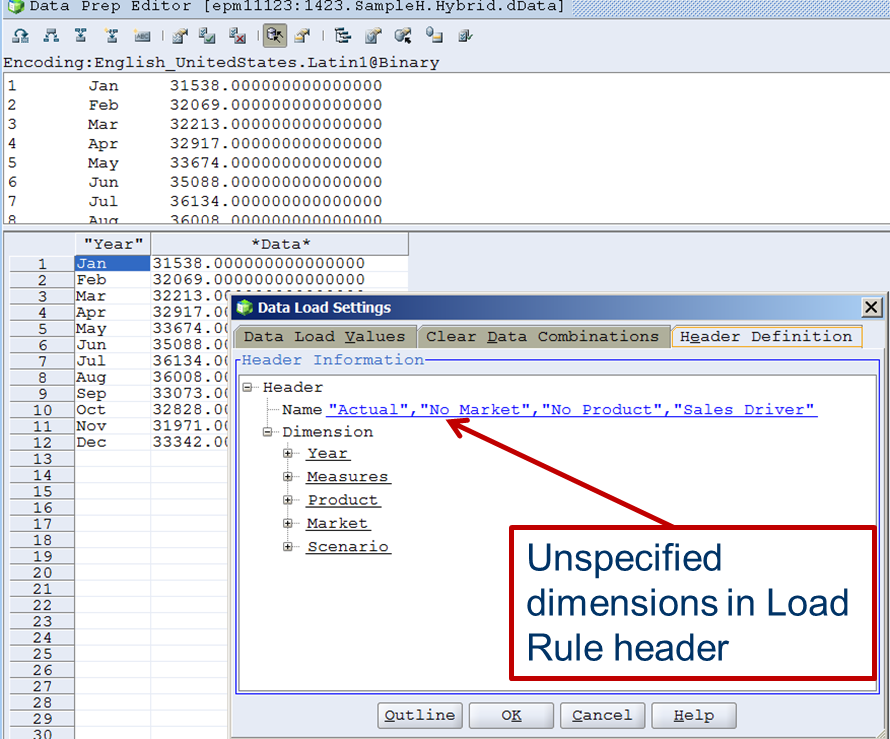
And now the calc
My oh my oh my we are finally here. The upper level data from that MDX query has now been loaded to level 0 buckets and the allocation code – which looks almost exactly like the BSO code ‘cos that’s what it is – can use those totals to perform the allocation.
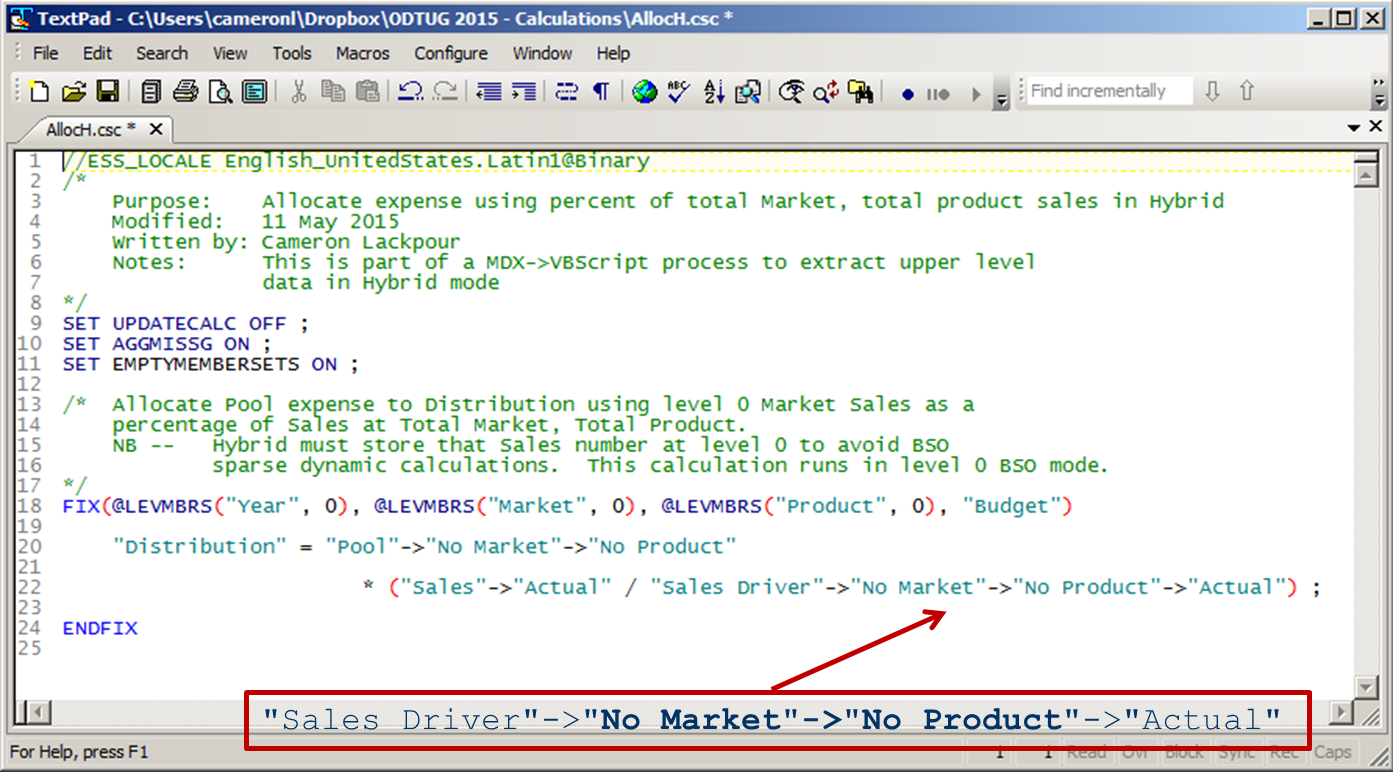
No aggregation is needed as this is Hybrid. ASO on top of BSO is the dream come true.
Wot’ll she do, mister?
While all of this has been great fun, this level of complexity better be worth the candle. Is it? After all, Sample.Basic isn’t exactly a large database – there is no Slow with that wee beastie.
Using the same Essbase database that Tim German and I have used for the past two years – 40,000 customers against 70,000 products along with the typical Planning dimensions, the Hybrid numbers speak for themselves.
Engine
|
Performance in seconds
|
BSO
|
117
|
Hybrid
|
6
|
Yowsa. Remember that 117 seconds assumes an already aggregated database. So if there were to follow the typical Planning approach of enter, agg, allocate, agg we’re looking at something more like four minutes. Four minutes vs. six seconds is an eternity when a business rule is run on form save.
In the Tree, part of the Tree
Is this fast? Yes.
Will you ever use this particular approach? No. At least I hope so.
The next post in this Stupid Trick will show a much saner, much simpler, and much more likely approach to allocations in Hybrid.
Be seeing you.