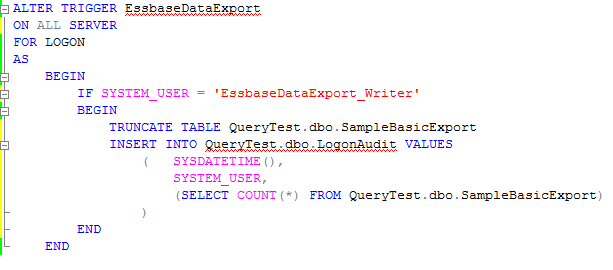
Introduction
This is the third and final installment of a three part series on ASO calculations, and specifically, ASO Planning calculations. Thus far I’ve showed how to use the @CalcMgrExecuteEncryptMaxLFile via Calculation Manager which is pretty cool, and then how to make ASO procedural calculations in MaxL fast, fast, fast. That’s all well and good, but how does that relate to ASO Planning?
I’m awfully glad you asked that, because these two hacks combine in ASO Planning to create ASO Planning procedural calculations that are both unbelievably fast and slick. Read on, and all will be revealed.
The path not taken
Before I go any further, you are likely thinking, (Are you? Really? Really? If so, you’re just as sad as I. We both should seek help.) ‘arf a mo’, Cameron, why wouldn’t you use the ASO procedural calculation functionality in Calculation Manager? Why indeed?
It isn’t as though ASO Calc Mgr procedural calculations aren’t available in ASO Planning 11.1.2.3.500 – they are.
But what is also there is a bug, and I have to say quite a reasonable one. I like to think of myself as the kind of person that can break anything, if I try long enough.
A short review
The essence of fast procedural calculations in ASO Essbase is (or would be) to use a NONEMPTY modifier in the calc script. Unfortunately, at this time that is not available although I understand it is somewhere on the product enhancement list. What my prior post explained in great detail was the hack Joe Watkins came up with to use the ASO procedural allocation grammar to copy the results of a member formula to a stored member. That member formula (dynamic, and in the case of currency conversion, only valid at level zero) can use the NONEMPTYTUPLE keyword to make Essbase only consider existing data and in turn it moves it to a stored member.
The next few paragraphs are a rip-and-read from that post but it’s short, explains everything, and I am too lazy to paraphrase all of it.
Additional member
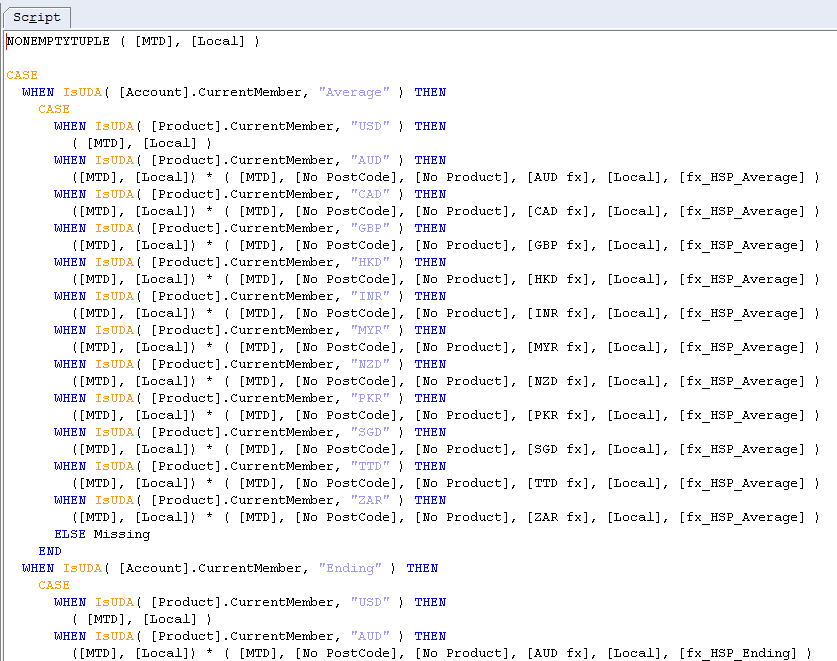
In the Analytic dimension of my Planning app, I created a calculate-only member called MTD USA. It contains the member formula to calculate fx conversion.

MTD USA’s member formula
Note the NONEMPTYTUPLE command that makes the member formula only address non empty data.
The CASE statement is a MDX version of the BSO currency conversion calc script.
Execute allocation
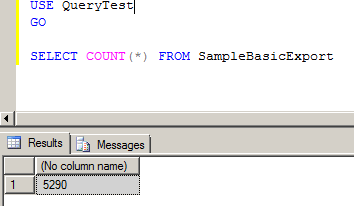
It’s all pretty simple from here on, thanks to Joe. All I need to do is kick off an execute allocation in MaxL, set up my pov aka my FIX statement, identify the source (Local) and target (USD). By not defining a spread range other than USD, Essbase copies everything from MTD USA in Local to MTD in USD.
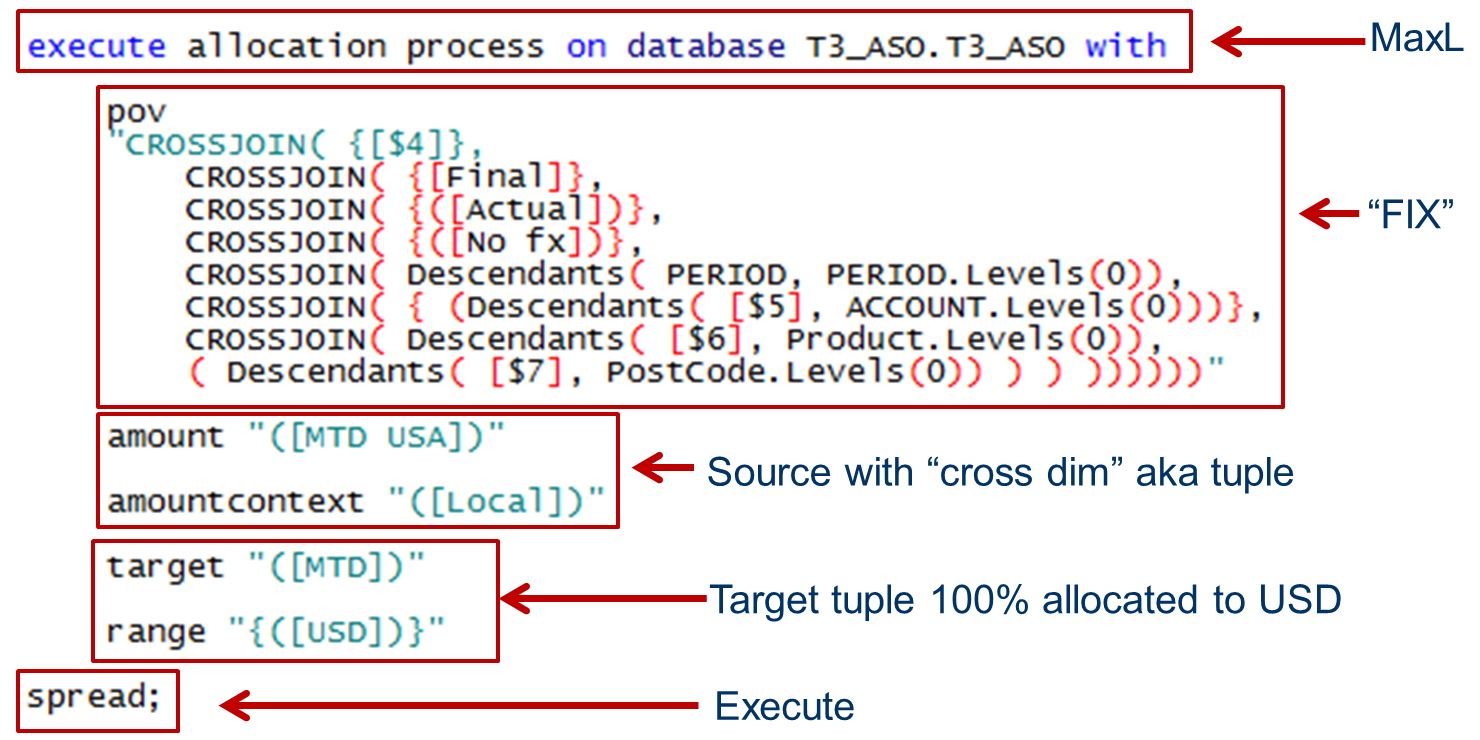
Did you see the $5, $6, and $7 in the code? If it’s MaxL, it can be driven through parameter variables.
Got it? MTD member formula with NONEMPTYTUPLE + ASO procedural allocation that allocates 100% of that dynamic formula member to a stored member equals fast, fast, fast.
So what didn’t work?
I know that the Calc Mgr team is quite proactive and I suspect that this bug will be fixed soon, but in the meantime, and because this is a Most Excellent Hack with lots of possibilities outside of Planning, I’ll show how to get round it.
Specifically, what went KABOOM?
Oracle never thought anyone would allocate 100% of a level zero member to another. And I can hardly blame them for thinking it.
Here’s the relevant screenshot in Calc Mgr. It (again, quite reasonably) assumes that when you allocate a data value, you do it from an upper level member all the way down to the bottom. And that is the normal way to do an allocation, except the fast ASO procedural calc hack doesn’t do that – it allocates a level zero member to a level zero member. And that doesn’t work.

How I solved this
I found this defect as I was writing the joint presentation I gave with Tim German for Kscope14 and I wasn’t exactly doing it months before conference. I was stuck.
But I remembered seeing the @CalcMgr functions back in Essbase 11.1.2.2. What if I could write a BSO Calc Mgr rule and drive an ASO procedural calc via MaxL?
And it turns out that in fact there are a lot of ways to run a MaxL script from BSO:
- @CalcMgrExecuteEncryptMaxLFile (privateKey, maxlFileName, arguments, asynchronous)
- @CalcMgrExecuteMaxLEnScript (privateKey, maxlScripts, arguments, asynchronous)
- @CalcMgrExecuteMaxLFile (user, password, maxlFileName, arguments, asynchronous)
- @CalcMgrExecuteMaxLFile (user, password, maxlFileName, arguments)
- @CalcMgrExecuteMaxLScript (user, password, maxlScripts, arguments, asynchronous)
- @CalcMgrExecuteMaxLScript (user, password, maxlScript, arguments)
- RUNJAVA
And it gets better
Once I realized this, it hit me that I could likely drive it off of ASO Planning forms and pass the Page, POV, and even the User Variable values on save into a BSO Calc Mgr rule and from there into a MaxL script that runs the allocation. OMG, Essbase ASO procedural calc nirvana could ensue. Or the end of the world. If igniting the atmosphere side bets are good enough for Manhattan Project physicists during atom bomb tests, surely giving this a whack seems worthwhile.
The short story is that all of this somewhat amazingly works, and works quite well. I’ll cover the straightforward setup and application of this and then go into some of the more interesting possibilities.
Doing it @CalcMgrExecuteEncryptMaxLFile style
You will remember from the first post that it is very important, if you only mean to run the ASO procedural calc once, to limit the scope of @CalcMgrExecuteMaxLFile to one and only one block. And oh yes, that block must exist for this to work. Here’s the code:
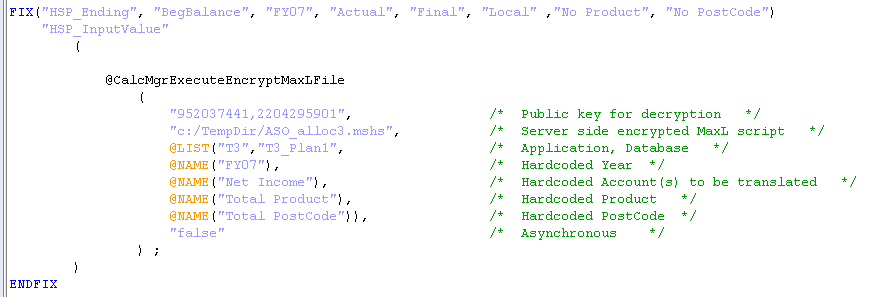
See part one for all this approach’s requirements beyond blocks. You will note that this BSO script does not have any Calc Mgr variables but I could have easily used them.
RUNJAVA, RUNJAVA, RUN RUN RUN
Again, see part one for all of the rules. Note that the FIX and the existing block requirements do not apply. But what I want you to focus on the {varYear}, {varBRUVAccount}, {varProduct}, and {varPostCode} Calc Mgr variables.
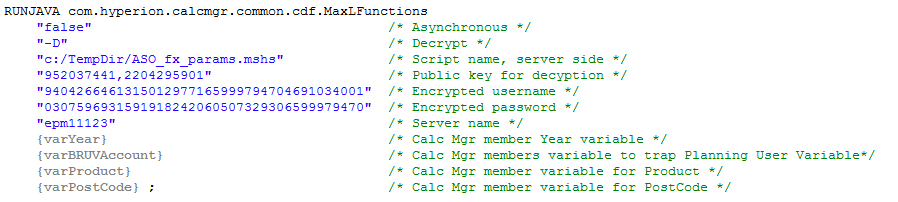
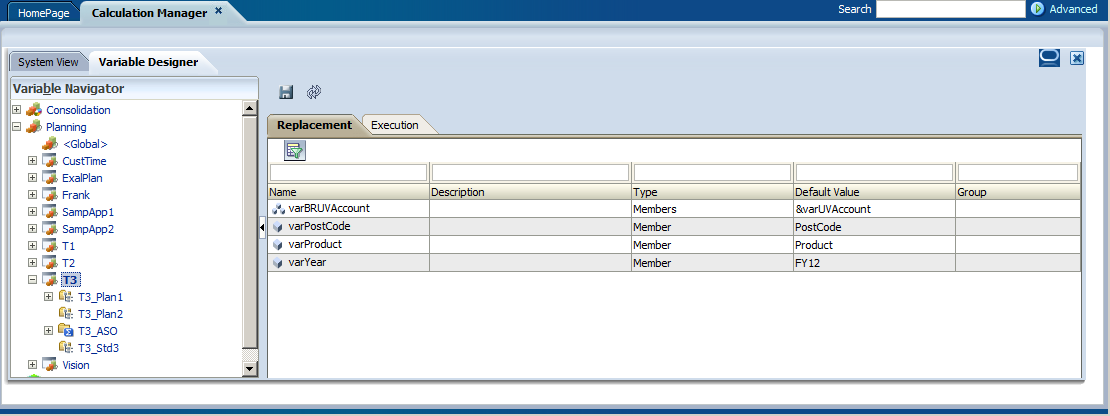
Here are the variables as defined in Calc Mgr. NB – These are Calc Mgr variables passed from an ASO to a BSO Calc Mgr rule. Coolness. And awesomeness. And a great hack.
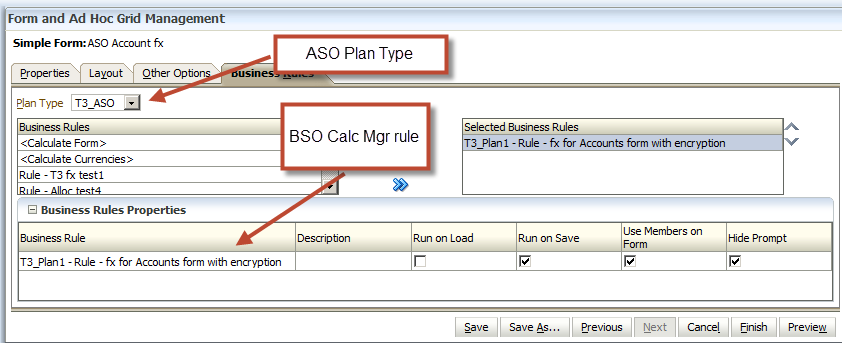
Here’s the (again, BSO) rule associated to the (again, ASO) form in Planning. Note the Use Members on Form tag:
ASO procedural calc
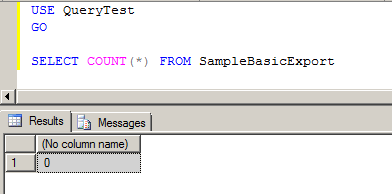
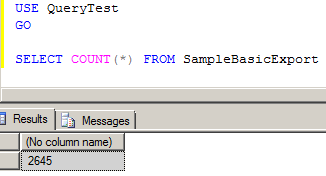
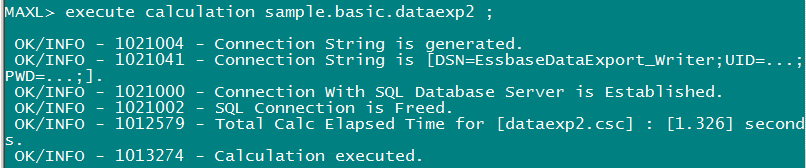
Here’s the MaxL code containing the ASO allocation script:
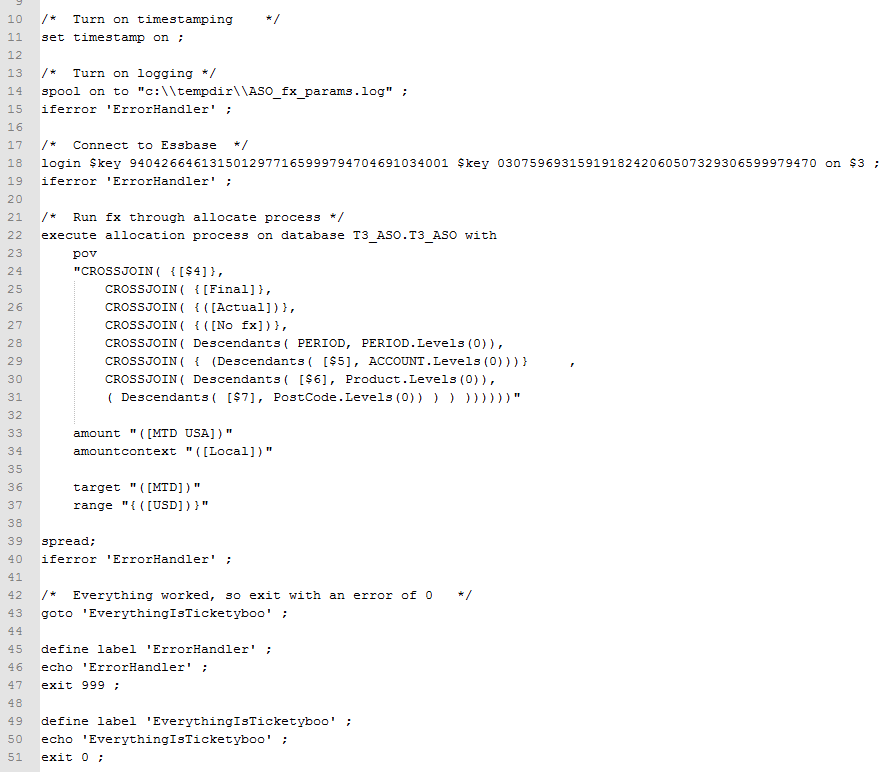
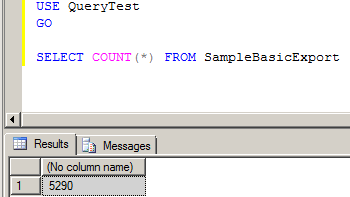
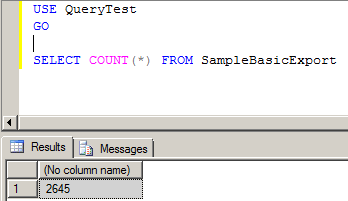
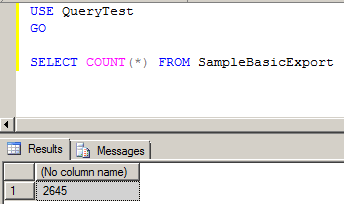
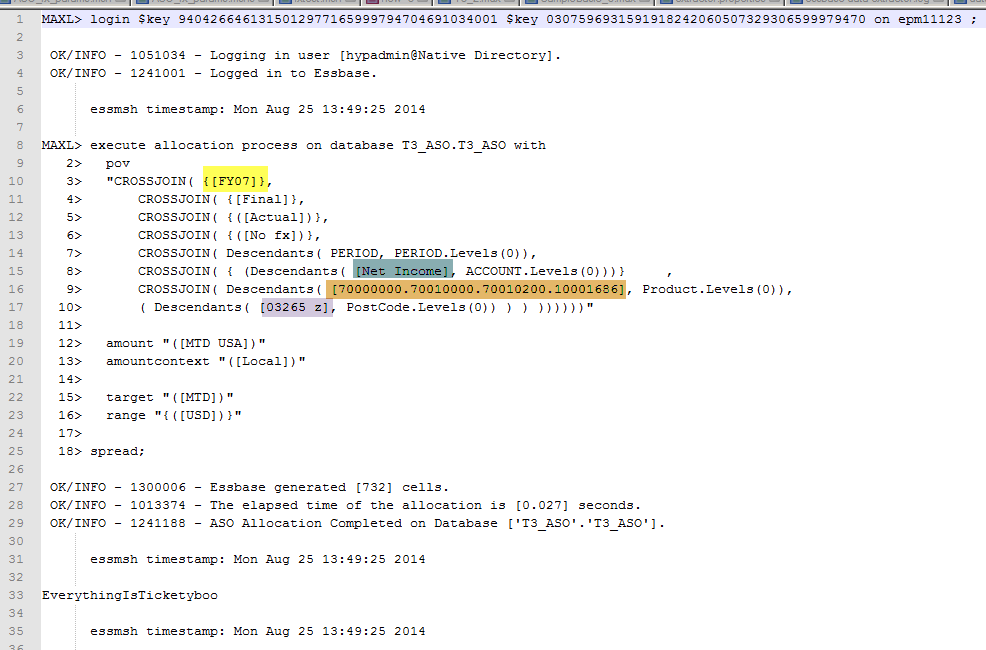
And the output from that fx conversion. Note how ASO Planning form values got passed to Calc Mgr variables and then to MaxL to run the ASO procedural calculation (see the pretty pastel highlight colors):
And now the demo
And here’s a very short movie showing it executing. Please excuse the editing (with clock) at the end as I was trying to spare you all the trauma of me searching for the calculation time in the Essbase application log. In any case, the time logged to MaxL (0.027 seconds) shows up in the application log as well.
Numbers don’t lie
Finally, you know from part two of this series how fast this can be. The times you are seeing below are slower than what I demonstrated because they represent full database size (my database is just a fraction of the full dataset because of disk space constraints – trust me, these numbers are real):
Process
|
BSO
|
ASO
|
X Fast
|
Allocate
|
106
|
3
|
35
|
Fx
|
400
|
1.2
|
333
|
Aggregate
|
1,772
|
N/A
|
N/A
|
Total
|
2,278
|
4.2
|
542
|
Using this technique, the ASO fx is over 300 times as fast as the equivalent BSO outline and data. A little slice of Essbase performance heaven, isn’t it?
Conclusion, or is it?
A combination of the Calc Mgr CDF that is in every copy of Planning (and Essbase, for that matter), the tried and true POV/page/and now row and column set passing to Calc Mgr, and a little creative ASO Essbase procedural calculations gives the Planning community access to an amazing amount of power and functionality.
Cool, eh? But this technique can be taken quite a bit further.
Where this starts getting really interesting
The demo you see above is from a Planning application that has BSO and ASO plan types that mirror one another. As such, the dimensionality in the BSO application mostly matches ASO. Is this required? Absolutely not.
In fact, all that I need to run ASO procedural calculations in Planning is a BSO plan type with exactly one block of data (for @CalcMgrExecuteEncryptMaxLFile) or one that is completely empty (for RUNJAVA) and I can then address any ASO Planning plan type, even ones across multiple Planning applications or even servers. The Calc Mgr functions call MaxL and MaxL can address any Essbase database to which it is provisioned whether that be that a Planning plan type, an ASO Essbase database, a BSO Essbase database, some combination of the above, etc., etc., etc.
Calc Mgr itself isn’t even required (or even Planning) if you wish – you could use this all in a pure Essbase database and use command line substitution variables to drive scope, or just hard code it all. You can go absolutely wild, relatively speaking, with this approach and do just about anything with it. It is a very powerful technique and one that I hope will be exploited.
I find this all oddly stimulating. But I’m weird.
Now the real conclusion and a question for you
This is one of my longer posts – almost 30 pages in Word which equates to approximately 6,500 words in total. Does it make sense to write multiple part posts like this or would the EPM community be better served with me trying to write things like this as a white paper? Write care of this blog or just email me.
Be seeing you.